15 years, 10 months ago by Adrienne Mamin
Egyptian Hieroglyphs on The Rosetta Stone were deciphered by scholars, but a new computer program written at MIT could potentially accomplish the same feat today:
“'Traditionally, decipherment has been viewed as a sort of scholarly detective game, and computers weren't thought to be of much use,’ study co-author and MIT computer science professor Regina Barzilay said in an email.” (quoted in this recent writeup in the National Geographic Daily News).
The language in this case is Ugaritic, written in cuneiform and last used in Syria more than three thousand years ago. Archaeologists discovered Ugaritic texts in 1928, but linguists didn’t finish deciphering them for another four years. The new computer program did it in a couple of hours.

While an exciting and significant first step, the program is not a silver bullet solution to language decipherment. Human beings figured out Ugaritic long before the computer program came along, and it remains to be seen how well the program works with a never-before-deciphered language. Furthermore, the program relied on comparisons between Ugaritic and a known and closely related language, Hebrew. There are some languages with no known close relatives, and in those cases, the computer program would be at a loss.
Of course, we can’t be certain exactly how the technology may progress in the future. But with the Rosetta Disk designed to last for thousands of years, and with hundreds of languages classified in the Ethnologue as nearly extinct, an automated decoder of language documentation seems likely to prove useful eventually. It’s nice to know we’ve made a promising start.
15 years, 10 months ago by Laine Stranahan
The Rosetta Project is pleased to announce the Parallel Speech Corpus Project, a year-long volunteer-based effort to collect parallel recordings in languages representing at least 95% of the world's speakers. The resulting corpus will include audio recordings in hundreds of languages of the same set of texts, each accompanied by a transcription. This will provide a platform for creating new educational and preservation-oriented tools as well as technologies that may one day allow artificial systems to comprehend, translate, and generate them.
Huge text and speech corpora of varying degrees of structure already exist for many of the most widely spoken languages in the world---English is probably the most extensively documented, followed by other majority languages like Russian, Spanish, and Portuguese. Given some degree of access to these corpora (though many are not publicly accessible), research, education and preservation efforts in the ten languages which represent 50% of the world's speakers (Mandarin, Spanish, English, Hindi, Urdu, Arabic, Bengali, Portuguese, Russian and Japanese) can be relatively well-resourced.
But what about the other half of the world? The next 290 most widely spoken languages account for another 45% of the population, and the remaining 6,500 or so are spoken by only 5%--this latter group representing the "long tail" of human languages:
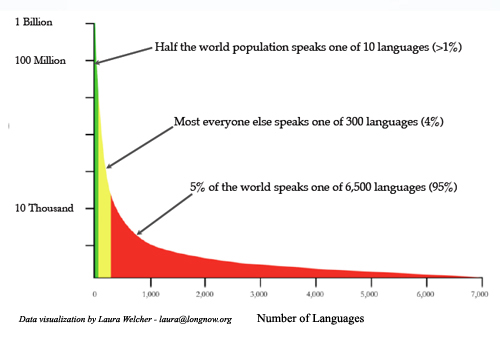
Equal documentation of all the world's languages is an enormous challenge, especially in light of the tremendous quantity and diversity represented by the long tail. The Parallel Speech Corpus Project will take a first step toward universal documentation of all human languages, with the goal of providing documentation of the top 300 and providing a model that can then be extended out to the long tail. Eventually, researchers, educators and engineers alike should have access to every living human language, creating new opportunities for expanding knowledge and technology alike and helping to preserve our threatened diversity.
This project is made possible through the support and sponsorship of speech technology expert James Baker and will be developed in partnership with his ALLOW initiative. We will be putting out a call for volunteers soon. In the meantime, please contact rosetta@longnow.org with questions or suggestions.
15 years, 10 months ago by Adrienne Mamin

Description of Yurok numerals
in the Rosetta archiveYurok (YUR) is the language of the Yurok people of northwestern California. As with most indigenous American languages, European contact has mostly come to replace Yurok with English, so that as of 2009 it is near extinction. Yurok belongs to the Algonquian language family, most of whose other members are geographically distant from Yurok. Accordingly, Yurok is surrounded by languages unrelated to it, except for the only distantly related (and extinct) Wiyot.
Yurok has a set of glottalized consonants (sounds produced with the glottis closed, as if holding your breath) that contrast with their nonglottalized counterparts. The glottalized sounds are less common but are important in Yurok morphology, such as verb conjugations.
Some verbs must inflect (be conjugated) for person and number, others cannot, and many can go either way. For example, the word for eating must take different endings according to the subject: nepek’ for ‘I eat,’ nepe’m for ‘you (singular) eat,’ nep’ for ‘s/he eats,’ nepoh for ‘we eat,’ nepu’ for ‘you (plural) eat,’ and nepehl for ‘they eat.' On the other hand, chek ‘sit,’ always maintains the same form no matter who and how many are sitting. Finally, skewok ‘want’ can remain skewok for all subjects, or it can inflect as skewoksimek’ ‘I want,’ skewoksime’m ‘you (singular) want,’ skewoksi’m ‘s/he wants,’ etc., just as the verb ‘eat’ does.
Yurok has no distinct category of adjectives; the words that translate to adjectives or express adjective-like meanings behave like verbs in terms of word order and inflection. For example, there is a word for being big that inflects just as verbs do: peloyek’ ‘I am big,’ peloye’m ‘you are big,’ pelo’y ‘s/he is big,’ etc. Numerals are also a type of verb, and they have different forms according to the type or shape of thing being enumerated (for example, humans versus animals, or flat things versus tufted things).
Ways of writing Yurok have varied over time and remain not entirely settled. In the 1980s the Yurok Language Committee adopted UNIFON, designed (by an economist) as an English pronunciation key. However, UNIFON was impractical and therefore unpopular, and the Yurok Language Committee adopted an alternative system, which was later revised by linguists working on the language (as Leanne Hinton details in her unpublished 2010 article "Orthography Wars"). The Berkeley Yurok Language Project, a searchable collection of Yurok stories, words, and morphemes, lists entries in both the original alternative system and the revised system.
