Steven Bird, Associate Professor in Computer Science at the University of Melbourne, and his team have developed an Android application for the documentation of language. The easy-to-use app was first tested in the field last year in Papua New Guinea, where Dr. Bird and his colleagues provided the Usarufa people with Android cell phones, equipped with the app, to record themselves speaking their language.
The Usarufa language is still spoken by only about a thousand people. The language was the first to be recorded with the new technology in the pilot project and also the source of the app’s name. The developers named their application Aikuma after the Usarufa word for “meeting”.
Speaker using the Aikuma app
The pilot project turned out to be very successful. The Usarufa speakers had no difficulties using the app after brief instruction and enjoyed recording their stories, personal narratives, songs and dialogues.
A more recent field trip led Dr. Bird and his colleagues to the Tembé people, who live in an Amazonian reservation in Brazil. The people are aware of the endangered status of their language, which has only about 150 remaining fluent speakers, so they invited the researchers into their remote village to help them preserve their linguistic heritage.
75 miles away from the nearest town, the villagers do not have internet access and are not familiar with the latest technological devices. The minimal design of the Aikuma app and the use of touch-screen phones allow for an intuitive method of recording. The speakers record themselves by just pushing the record button, holding the phone to their ear and talking as if they were making a phone call.
A particularly useful feature of the app is the ability to add a time-aligned audio translation. Most of the minority language speakers in Brazil speak Portuguese as well. A translation of the recordings in a language that is more widely spoken can help ensure that the content of the recordings will be understood even if the language loses its last speakers in the future.
Steven Bird talking about his current field work in Amazonia
In the past field linguists tended to focus on producing written documentation, but the transcription of speech with the International Phonetic Alphabet is a very time-consuming task that can take up to an hour for each minute of spoken language. The documentation of severly endangered languages is a race against time and recordings of the actual language in use can only be made while there are speakers left. Dr. Bird points out the importance of recording endangered language speakers:
"We collect and archive language recordings now while the speakers are still alive. That’s all. We have the whole of the future to transcribe and process the recordings...The living speakers of today’s disappearing languages are equipped to preserve their voices, their unique perspective on the world, and how they have managed to live sustainably in their homeland for centuries."
The research team found only six fluent speakers in the village, but they were all keen on recording their Tembé stories and legends and translated them into Portuguese as shown in the video below.
The most recent field trip lead the researchers to another Amazonian tribe, the Baré. However they couldn't find any fluent speakers of this endangered language, and found that everyone had shifted to the more widely used Portuguese or Nhengatu - a language that is undergoing shift as well, but is still spoken by about 20,000 people.
The Nhengatu speakers recorded some of their stories using the Aikuma app and
it struck Dr. Bird how one of the speakers gestured with one hand while speaking. From an anthropological as well as linguistic point of view gestures are a rich source of information. The speakers also enjoyed making video recordings of each other, and this was particularly helpful when an elderly speaker wasn't able to manipulate the touch-screen in order to make a recording. A solution to this and a further development of the Aikuma app prototype could be to change the format from audio to video in order to capture this additional information and let the speakers create video recordings of each other.
The pilot projects turned out very successful and insightful in both preserving some of the stories and languages of the peoples involved as well as providing the developers with ideas on how to further improve the Aikuma app so it can be used successfully for the documentation of endangered languages in even the most remote places.
Throughout the world indigenous and minority languages are losing ground and are being displaced by more dominant languages of wider communication. This trend has often resulted from historical injustices commited against indigenous peoples.
But the recent times have seen the formation of a growing number of indigenous communities reclaiming their endangered or even extinct heritage languages.
The Master-Apprentice Language Learning Program is one such initiative, pairing a proficient speaker of a given endangered language, the master, with an adult non-speaker eager to learn their heritage language, the apprentice. Developed by Leanne Hinton, professor emerita at the University of California, Berkeley, and the Advocates for Indigenous California Language Survival, this successful program has spread throughout the United States and other countries like Canada or Australia.
In her new book, Bringing Our Languages Home: Language Revitalization for Families, Hinton takes it a step further and brings language revitalization to the place where languages are really learned: the family.
The 13 case studies at the heart of the book are representative for the growing number of parents who want to enable their children to grow up with their heritage language even though they themselves might not have had this opportunity. Hinton turns the floor over to these 13 families and minority language advocates to tell their stories in their own words. The result is a book that is engaging and useful for linguists as well as anyone with an interest in the preservation and revitalization of endangered languages.
The backgrounds of the families portrayed cover a wide range - geographically as well as in the languages that are being revitalized and the context this occurs in. For some of the languages there’s still a sufficient number of native speakers to learn from. Some are being taught in immersion school programs. Other languages, as in the case of the native American Myaamia and Wampanoag, were not spoken in generations. Nevertheless, Daryl Baldwin and jessie little doe baird, who tell their stories in the first two chapters, did not shy away from this challenge, invested years of their lives to get degrees in linguistics and became experts in their respective languages. They are reaping the rewards of their efforts when they hear their children speak the language of their ancestors that had been silent for so long.
But despite the difference in initial linguistic circumstances, there’s one striking parallel in all the narratives: the constant resistance against the dominance of the ubiquitous English language. Of course, English is just a placeholder for any dominant majority language and just happens to be the national language in all the narratives (the families living in the USA, New Zealand, Ireland and Scotland respectively). But it is symbolic of the influential status of majority languages endangered languages all over the globe have to be able to compete with if they are to survive and thrive.
Bringing Our Languages Home is not just a collection of case studies but also a practical guide for families who want to venture the reclamation of their languages. The variety of starting conditions and external factors as well as the assets but also obstacles portrayed in the personal narratives give interested families a realistic impression of the revitalization of a language in the family setting. Moreover, in the final chapter Hinton sums up what we can learn from these pioneering families and complements this with hands-on tips and approaches to language revitalization for nearly any linguistic point of departure.
Leanne Hinton’s Bringing Our Languages Home: Language Revitalitation for Families is a ray of hope for even the most endangered language communities without glossing over the challenges that inevitably go with the revitalization of fragile languages in the omnipresence of established languages like English.
The Endangered Languages Catalogue (ELCat) is a project by the University of Hawai’i at Manoa and Eastern Michigan University, supported by a National Science Foundation grant. The project aims to compile a comprehensive up-to-date catalogue on all languages considered to be in danger, providing information on:
the number of speakers, age of the youngest speakers and location of each language
the genetic affiliation to a linguistic family for every language and
an account of the documentation and data that already exist on any given language of the database.
The three-year project was initialized in 02011 and is planned in two phases. In Phase I data crucial in determining whether a given language is in danger was gathered by linguistic research teams at both universities. This phase has just been completed and the findings are available on the website of the Endangered Languages Project, the public portal of the ELCat helping raise awareness of and gathering data on endangered languages.
Endangered languages in the USA (click on the image to browse this interactive world map)
The Endangered Languages Project (ELP) is an initiative of the newly formed Alliance for Linguistic Diversity, a coalition of international linguistic and cultural organizations, and Google. The Rosetta Project and PanLex Project at The Long Now Foundation are also members of the Alliance. ELP is different from similar projects in that it is a community-driven resource. Anyone involved with endangered languages is invited to contribute to the database. This way endangered language communities as well as researchers working with them can upload, update and correct the available information and help expand the database in a collaborative effort.
The first results of this collaboration have been presented by Lyle Campbell, ELCat Project Director and linguistics professor at the University of Hawai'i at Manoa, during the 3rd International Conference on Language Documentation & Conservation (ICLDC 3). The updated and newly compiled data allowed the researchers to determine which of the world’s living languages are at risk of dying out and to what extent each individual language is endangered. In order to determine whether a language is at risk, ELCat has developed the Language Endangerment Scale. The Ethnologue, a well-established comprehensive language catalogue for basic information of all living - not only endangered - languages, presented their own newly-developed scale for language endangerment, called EGIDS, at the same conference. ELCat's scale is different in that it has a smaller set of criteria, focusing exclusively on endangered languages, which serves the purpose of the Endangered Languages Catalogue. Still, there are some parallels to EGIDS. On the basis of four criteria, ELCAT's Language Endangerment Scale assigns six different levels of endangerment to each language, ranging from 0 - Safe to 5 - Critically Endangered. The criteria are:
Intergenerational Transmission (How old are the youngest speakers and is the language passed on to younger generations?)
Absolute number of speakers
Speaker number trends (Is the number of speakers declining, stable or increasing?)
Domains of use of the language (Is the language only used in certain (e.g. informal) contexts or for every domain in life from home to media, education and government?)
The findings yielded by this scaling and the updated database provide us with new knowledge on language loss. Earlier estimates lead to the prospects of the death of 50-90% of the world’s languages by the end of the century. Another claim that has been made very frequently when talking about language endangerment is that one language goes extinct every two weeks. Both estimates are, however, not in accordance with ELCat’s new data as presented at the ICLDC 3 earlier this month.
The source of the prediction of the death of up to 90% of all languages by the end of the 21st century is a 01992 paper titled The World's Languages in Crisis [1] by Michael Krauss, professor emeritus of the University of Alaska Fairbanks and expert on the indigenous Alaskan language Eyak, whose last native speaker passed away in 02008. Krauss arrived at this estimate based on the best available sources at that time. This paper and the presentation Krauss gave on that topic at the Linguistic Society of America's annual meeting in 01991 can be seen as a pivotal moment for the awareness of language loss.
Over two decades later, on the basis of ELCat’s much more comprehensive database (and recent results of the Ethnologue support this), we know that Krauss’ estimates were too high.* The application of the Language Endangerment Scale to all known languages has revealed that a total of 3,176 can be considered to be endangered. This is about 46% of all living languages, far from Krauss' 90% worst case scenario. Nontheless, Krauss’ lower threshold of 50% might after all become sad truth if endangered languages keep losing ground.
Another number that had to be corrected is the estimated extinction of one language every 2 weeks. This figure has been repeated so often in the discourse on language death that it is hard to trace back where it originated from. Even though Krauss did not make this claim, it seems most likely that it was calculated based on the estimates presented in his paper, as for instance linguist David Crystal did in his 02000 book Language Death (p. 19). [2]
ELCat's new findings, however, suggest that language death progresses at the rate of about one language in three months rather than two weeks. [3] This estimate is based on the number of languages that we know have become extinct in the recent past rather than estimates of how many languages might go extinct in the future.
Though it is good news that language loss is not proceeding quite as quickly as we previously thought, this does not mean that linguistic diversity is on the safe side. The looming loss of almost half of the world’s languages is sufficient proof for the “ongoing crisis of language loss," as Campbell phrased it. The new findings also show that the rate at which languages die out has highly accelerated in the last half century. Campbell concluded:
"These losses are still horrendous…There is no need to repeat the inaccurate claim [that one language goes extinct each two weeks]...What we see is shocking enough."
Today 457 or 9.2% of the living languages have fewer than 10 speakers and are very likely to die out soon, if no revitalization efforts are made. 639 of the languages known to have existed are already extinct – 10% of all languages.
Moreover, we now know that since 1960 we have lost as many as 28 entire language families. This is even more devastating from the viewpoint of linguistic diversity. A language family is a group of languages that have emerged from a common proto-language. Linguists can reconstruct such relations if a set of languages share certain grammatical and phonetic features. The number of languages in a language family can vary from over a thousand (as in the Niger-Congo and Austronesian language families) to just a few. Languages that cannot be related to any other language are called isolates. The language family with the most speakers is Indo-European, encompassing languages like English, Spanish, Russian or Hindi - just to name a few of the over 200 languages belonging to this family. But a language family does not have to have 3 billion speakers, as in the case of Indo-European, for its extinction to have a considerable impact on linguistic diversity.
ELCat uses the metaphor of biodiversity to illustrate the gravity of the loss of an entire language family: If we compare the extinction of a language to the extinction of an animal species, the death of a language family would equal the loss of a whole branch of the animal kingdom, for example all felines.[4] We know of a hundred language families that have gone extinct over the course of history - 24% of the world's linguistic diversity. But the fact that 28 of them have gone extinct over the relatively short time span of the last 50 years is symptomatic of the accelerated rate of language loss we are experiencing in recent times.
Now that all available information on the entirety of endangered languages has been gathered and updated, the next step in the ELCat project is to fill the gaps, expand the available data and introduce a measure of how much documentation exists for each of the 3,176 endangered languages. The ELP website already provides some bibliographical references on existing documentation for a number of languages, alongside all sorts of texts, video and audio material uploaded by researchers or native speakers. The aim for Phase II of the ELCat project is to complete this information, especially for languages where there has been very little information to date.
The purpose of the information provided in the database is manifold. It allows researchers to work collaboratively on the expansion of the information, it aims to point to and interest linguists and future researchers in the least documented languages, it invites endangered language speech communities to contribute information on their language and provides material for preservation and revitalization programs. ELCat and the Endangered Languages Project hope that this way their community-driven database helps raising public awareness of language endangerment and can contribute to stopping or reversing the language loss.
Listen to Lyle Campbell's talk at the 3rd International Conference on Language Documentation & Conservation.
[1] Krauss, Michael E. 1992. The World's Languages in Crisis. Language 68(1): 4-10.
[2] Crystal, David. 2000. Language Death. Cambridge: Cambridge University Press.
*New findings of the Ethnologue suggest that the state of languages in Australia, New Zealand and Northern America is very close to this estimate with only 9% of the languages of Australia and New Zealand and 7% of the languages of the USA and Canada still being vital, the rest being in danger (or extinct). On a global scale, however, considering e.g. the vitality of 80% of Subsaharan languages, this estimate is too high.
The Ethnologue is a comprehensive language catalogue which is used as a reference work by linguists all over the world. It was published for the first time in 1951 by The Summer Institute of Linguistics (SIL) and provides information for all known living languages and languages that have become extinct after 1951. The Ethnologue provides statistical data on the world's languages including native speaker populations, literacy rates, regions where the languages are spoken, an assessment of their vitality and other basic information. This data is very useful as a reference point for language projects of all kinds. The set of data as a whole is important infrastructure that is also used by the Rosetta Project. Some of the language metadata in the Rosetta Collection at the Internet Archive, like the three-letter language identifier codes, are taken from the Ethnologue. The 17th edition of the Ethnologue has just been released online where it is browsable not only for linguists and researchers but for anyone interested in the languages of the world.
The Ethnologue is updated with a new edition approximately every four years to represent our best knowledge about the languages of the world. Altogether the new edition features nearly 60,000 updates and corrections and with each new edition the database is not only updated but also expanded. The 17th edition provides statistics for 7,105 known languages, adding 196 languages to the previous edition. Still this huge database makes no claims of completeness.
Where do all these new languages come from? Determining what constitutes a distinct language is not a straightforward task. Sometimes what we thought were dialects of a single language might get reclassified as separate languages, if it turns out that they are not mutually intelligible. Cultural identities and politics can also occasionally play a role in deciding where to draw the line. Determining whether a language is extinct can be an equally difficult task. In the new edition of the Ethnologue 188 languages have been reclassified from extinct to “dormant”, because they still have a symbolic value for their former speech community and offer the potential for revitalization or may be actively being revitalized. From time to time previously unknown languages are also discovered, as in the very recent announcement of Hawai’i Sign Language. Researchers report these findings to the constantly growing database of the Ethnologue.
With the new Ethnologue edition the website was also given a new, more interactive design which allows you to browse languages not only via the search function but also by clicking on a world map. For many countries there are language maps available that show in which regions certain languages are spoken. Two other new features that might be interesting for language enthusiasts are the Ethnoblog and the Language of the Day Feature. Every day a language is highlighted on the website with a link to its individual language page. The language pages provide the most important information on each, individual language, including the language status and its position in the language cloud - two new metrics in this version of the Ethnologue.
The language status is measured with the Expanded Graded Intergenerational Disruption Scale (EGIDS), which assigns each language a level of endangerment between 0 - International (e.g. English) to 10 - Extinct. This scale is an expansion of the eight-level GIDS-scale developed by linguist Joshua Fishman in 1991. GIDS was developed to determine the vitality of endangered languages, while EGIDS is applicable to all languages, including world languages and extinct languages, which makes it possible to assign a status to each language of the Ethnologue’s comprehensive database.
The language cloud is a visualization of the vitality of the world’s languages. It combines the EGIDS scale with the number of first language speakers of a given language to position its status of endangerment with respect to all other languages in the world. Each of the 7,105 languages listed in the Ethnologue is represented by a dot. Languages that have a lot of native speakers and are widely used are positioned in the upper left corner while the languages in the lower right corner are extinct or severely endangered languages with a very small number of speakers if any. Every language page features a version of the language cloud with the language’s individual position highlighted (see image).
Mindiri(a language of Papua New Guinea and Language of the Day for March 20, 02013) in the language cloud
The Ethnologue also provides the ISO-codes for all the listed languages. ISO 639 is an internationally recognized coding system of languages. SIL has been the official Registration Authority of the third and most extensive version of the code set, known as ISO 639-3, since 2007. Language names alone do not suffice as uniquie identifiers for any given language since some languages have multiple names and then again other language names are used for a number of languages. The ISO-codes ensure that every language is identifiable by its individual three-letter code.
An interesting side note: there is an ISO-code for not only each of the known living, but also extinct and constructed languages. Esperanto is an artificial language, but has 2 million speakers world wide according to the Ethnologue. The ISO-code for Esperanto is epo. Klingon, another constructed language, might not have as many speakers, but there is an ISO-code for it: tlh. Old English is not included in the Ethnologue because it died out centuries ago, but it still has an ISO-code (ang).
Do you know the ISO-code for the language or languages you speak? Why don’t you look it up in the new edition of the Ethnologue!
On Sunday linguists announced the discovery of a previously undocumented indigenous sign language at the University of Hawai’i. This is the first time a new language - spoken or signed - has been discovered in the USA since the 1930s! The language, they found, has been in use since at least the 1820s, but only few knew of its existence. Thanks to Linda Lambrecht, a committed native user of the language, Hawai’i Sign Language (HSL), as the language is now officially called, has been brought to the attention of the wider public for the first time in its history.
Lambrecht, who is an American Sign Language (ASL) instructor at Kapi‘olani Community College, grew up with HSL as a first language and had been advocating the use and preservation of it since the 1980s. With the launching of a HSL language documentation project, funded by the Hawai‘i Council for the Humanities and a number of other academic institutions, her work finally came to fruition.
In order to determine whether HSL is an independent language rather than a dialect of ASL, the researchers interviewed 21 native HSL signers on four of the Hawaiian islands. They found that eighty percent of the basic vocabulary differs from ASL, which makes the two languages mutually unintelligible and proves that HSL is a distinct language entirely unrelated to ASL. An analysis of the grammar has also confirmed that HSL is a full-fledged language rather than an unstable pidgin.
The “discovery” of HSL came just in time. Even though it used to be the native sign language of Hawai’is Deaf community in the 19th and early 20th centuries, it had been gradually displaced by ASL from the 1940s on. By the 1950s ASL was the dominant sign language in Hawai’i. Today there are only about a hundred Hawaiians left who know the language, most of them over sixty years old. One aim of the research project is to use the documented data for a dictionary, textbooks and HSL classes. This way, the researchers hope, Hawai’i Sign Language can be preserved and saved from dying out with the last generation of its native signers.
Today mother tongues will be celebrated world wide. This date was chosen by UNESCO in recognition of the Bengali language movement, where on February 21, 01952, students protested for their language to become an official national language. Several protesters taking part in the demonstration were killed by police. The celebration of International Mother Language Day reminds us of the importance of linguistic diversity and the human right to use one’s mother tongue, no matter how few speakers it might have, to be preserved and passed on to future generations.
The theme of this year’s International Mother Language Day is Books for Mother Tongue Education. This theme highlights the importance of mother tongue education for the survival of linguistic diversity. For a large number of languages there are no books or teaching materials. But with a majority language being the language of instruction at school, children of minority language speech communities have little chance to become literate in their mother tongue. Also many young speakers are prone to switch to a globally more dominant language when they realize that the use of their mother tongue does not allow them to take part in all walks of modern life. Mother tongue education is an important step towards preserving the world’s language diversity for the future.
Today and in the coming days people all over the globe are celebrating this diversity in a variety of events. Do you want to help raise awareness of the importance of linguistic diversity? You could help The Long Now Foundation's PanLex Project translate “mother tongue” in as many languages as possible. You could also print the official International Mother Language Day 02013 poster and hang it at school or work. For more ideas on how to get involved, visit the UNESCO's website.
Speech recognition software is everywhere—businesses use it to streamline customer phone calls, digital dictation software allows you to speak emails and essays, and, most recently, the iPhone’s surprisingly cheeky Siri can call, text, or look up information online with just a few verbal commands. With the aid of Deep Neural Networks, a mathematical technique patterned after human brain behavior, researchers at the University of Toronto and Microsoft Research have found a way to increase the accuracy of speech recognition to around 85%. This complex and relatively new technology is promising on its own, but when integrated with advanced translation software, has been used to produce a prototype of what could one day become a simultaneous personal translator, not unlike the iconic Universal Translator of Star Trek.
Though not mounted on a communicator pin or ready to communicate with aliens, this technology is still highly advanced, with multiple steps. First, the original speech is translated word-for-word into the second language. Next, the translated words are rearranged into grammatically appropriate phrases in the target language. The resulting translation is then spoken, not in the stilted, metallic voice of a computer, but in your own voice! To do this, an hour or so of recordings of your voice and that of a native speaker’s of the target language are necessary in order to preserve the speakers vocal identity while also creating comprehensible expressions in another language.
There are still some kinks to work out, of course, but the possibilities this suggests for overcoming language boundaries are worth thinking about. Conversations between cultures could become more balanced: neither party would feel as though they were “imposing” their language on the other, and both could speak in the tongue they find most amenable. In diplomacy, business, travel and the arts, this new translation tool could produce profound breakthroughs in communication and more importantly, understanding between cultures and people. As anyone who has used a translation site knows, computer generated translations can often go comically awry, and this program certainly runs the same risk of miscommunication as any other. All the same, the thought of hearing your own voice in another language is a bizarre and fascinating prospect, one that will hopefully attract researchers and language lovers alike to search for solutions.
One only hopes that this technology will be adapted not only to serve speakers of Chinese or French but also of lesser known languages. One positive development on this front is Microsoft’s adaptation of Haitian Creole and the Hmong language for its Bing translation service. This slow but thorough aggregation of diverse languages will ideally make it so that eventually no language community, however small, is left without a voice in global discourse — even if it is a computer generated one.
If you would like to see a video of this process in action, check out the video above of Microsoft's Chief Research Officer Rick Rashid speaking in English to a Chinese audience.
Most of us don't give much thought to character encodings. As our Web
browsers move effortlessly between Arabic and Cyrillic pages, we may
not remember the bad old days, when conflicts among dozens of
standards made it very likely that a document or Web page would appear
as utter gibberish. Some of those old encodings are still in use, but
most of today's browsers, Web sites, and applications comply with the
Unicode Standard and its encoding forms (UTF-8 being the most
popular).
Some Unicode Symbols for Egyptian Hieroglyphs
The name Unicode embodies the three original goals of the standard:
universality (encompassing all human languages), uniformity (using
fixed-width codes), and the uniqueness of each character
representation. In Unicode a unique number, or code point, is
assigned to each of thousands of characters in dozens of scripts.
Development of the standard began in 1987; today it's maintained and
promoted by the Unicode Consortium, a nonprofit whose members include
Apple, Google, Microsoft, and every other major tech company (Long Now's PanLex project is an associate member).
You can see all the Unicode characters and symbols by browsing the code charts, or
you can use one of several nifty tools developed for exploring Unicode.
Here are just a couple:
Unicode
Utilities. This interface to the Unicode database will tell you
more than you ever wanted to know about the character at each code point. Click on
"character" to type or paste any character and get a full list of its
properties. Click on "confusables" to see which characters can
accidentally (or
maliciously) be confused with others that look similar.
UniView. Developed
by Richard Ishida (Internationalization Activity Lead at the World
Wide Web Consortium), this app allows you to search or browse for any
character and discover all its properties. You can search by code
point, character, or the name or description of a character. Search
for the word "tilde" and you'll get 110 characters; search for "chess"
and you'll get symbols for all the chess pieces, in white and black (♔, ♞, etc.). A "lite" version of the
app is meant for mobile devices but may also be less intimidating
to a new user than the full-featured version.
Next time you translate some text online and then paste it into a
document, take a moment to thank the hard-working developers and
maintainers of the Unicode Standard. They've spent 25 years thinking
about character encodings so that you don't have to.
Cherokee has become the first Native American language to be fully supported by Gmail. As the 57th Google interface language, Cherokee can now be used to compose emails as well as perform web searches. The news reveals another exciting collaboration between a large technology company and members of the Cherokee Language Technology Department, who also worked with Apple in 2010 to develop full Cherokee language support for the iPhone, iPod and iPad.
Cherokee makes use of a unique writing system which was developed in 1821 by a member of the Cherokee Nation named Sequoyah. Although reminiscent in style of some Latin, Greek and Cyrillic scripts, each of the 85 Cherokee characters indicates a syllable of speech rather than an individual sound. For instance, the word “Cherokee”, is composed of the three characters “ᏣᎳᎩ”, each representing the syllables “tsa” “la” and “gi” respectively. Upon official adoption by the Cherokee nation in 1825, the writing system spread rapidly across disparate Cherokee territories.
Although currently reported to be spoken by around 16,000 people, a 2002 survey by the Cherokee Nation revealed that fluency in the language is exclusive to those over 40 years old. Connecting Google and Cherokee directly addresses the tribe’s younger generation by making the language both relevant and useable for everyday tasks such as sending an email. The language is not only being preserved, but also promoted, modernized and made accessible.
Levenger has just announced a set of gifts in their holiday catalog sure to please the multilingually-minded. Rosetta helped with the concept of one of these gifts - a set of multilingual learning blocks. The set of blocks is based on the "Swadesh List" - a set of basic vocabulary words that are found in most languages, because they have to do with basic human experience - our families, our bodies, and our natural environment. Each of the 28 blocks has a different word in commonly taught languages: Spanish, simple Mandarin, French, German, Latin and English.
Levenger is also rolling out several other multilingual gifts for the holidays, including this beautiful set of Cherokee Syllabary blocks:
You can read about some of the other gifts, and Levenger CEO Steve Leveen's interest in promoting multilingualism in this post on his blog.
We are delighted that Levenger is a supporter of the Rosetta Project.
This month the world’s linguistic diversity took another high-profile hit with the loss of the dialect Cromarty. Bobby Hogg, the last native speaker, passed away in early October and was mourned internationally, along with his unique linguistic knowledge. Starting in the 01950s, the traditional fishing methods of the remote village of Cromarty began to be replaced and industrialized. In turn, the formerly strong bond between the village’s cultural, economic and linguistic identities started to erode. By 02011 Bobby was the only remaining speaker of the dialect. He and his brother can be heard speaking Cromarty in these recordings hosted by the Highlands cultural archive Am Baile.
Cromarty was a dialect of Modern Scots; a language with numerous spoken varieties, mostly found in the Scottish lowlands, with a total of around 200,000 speakers. Despite being part of the same linguistic family, the dialects of Modern Scots differ from each other so greatly that they often lack mutual intelligibility. For instance, a speaker of Northern Scots, although only separated by a few hundred miles, may not understand or be understood by a speaker of Southern Scots. The highly distinctive nature of Scots dialects means that each variety, such as Cromarty, is a crucial element in the unique linguistic landscape of Scotland.
The loss of Cromarty is undoubtedly both significant and tragic, but it is essential to recognize that even in death, languages and dialects leave us with more than cause for lamentation. Perhaps most notably, the death of Cromarty tells us a great deal about the role of culture and community in the complex phenomenon of language loss. With its origins in a traditional fishing village, the dialect was highly specialized for talking about particular nautical techniques and equipment but simultaneously vulnerable to obsolescence as a result of technical and practical developments in this field. The recorded vocabulary of the Hogg brothers is peppered with these highly culturally specific terms such as “beetyach: a small knife for beeting (mending) nets” and “aave: the boy who acts as scummer (bailer) as well as the instrument he uses”. Understandably, as these tools, roles and techniques began to disappear, the words used to refer to them followed suit.
Additionally, for communities in similarly precarious cultural and linguistic situations, the disappearance of Cromarty may well reveal the truly precious nature of regional languages and dialects. The island of Tangier, set in the Chesapeake Bay, Virginia, plays host to an equally intriguing dialect. Like Cromarty, the Tangier Tidewater dialect is similarly tied to the local fishing methods and, as a result of its dramatically remote location, is hypothesized to sound similar to the English spoken by original American colonists. As such, in addition to encoding unique cultural information about the Tangier community, this dialect potentially reveals tantalizing details about the history and evolution of the English language. Understanding the sudden vulnerability and subsequent loss of Cromarty may be key in equipping communities such as Tangier with the tools and motivation to record, document or even galvanize the use of their own tongue.
Finally, the lesson of Cromarty reveals the importance of thorough documentation and archiving when dealing with highly endangered languages. In the final years of Cromarty’s use, a number of researchers (primarily Janine Donald) set about recording the dialect, as spoken by the Hogg brothers, with the hope of preserving and publicizing their unique tongue. Research findings, along with numerous original audio clips were published in an easily accessible online cultural archive named Am Baile as well as being printed in this document for local, public distribution. Since the death of Cromarty, these materials have delivered key information about the dialect’s words, phrases and sounds as well as providing fascinating cultural insight into the lives of Cromarty residents, to a truly international audience. Although these documents are by no means exhaustive, they set a great example of responsible and culturally sensitive ways to record, document and potentially preserve a language.
The Transcribe Bushman project was recently developed by Ngoni Munyaradzi, a master's student at the University of Cape Town's Computer Science Department. The goal is to transcribe the large number of manuscripts of |xam and !kun language documentation in the Bleek and Lloyd Collection.
To get through the laborious transcription process sooner rather than later, Ngoni Munyaradzi has developed an elegant interface where anyone can log in and help. One of the most impressive aspects of the interface is his elegant system for entering complex characters needed to capture some of the most complex phonetics found anywhere in human language:
As Khoisan languages, |xam and !kun are famous for having clicks as consonant sounds, several of which are written with unique symbols not used in other writing systems. They also have several tones, as well as many secondary articulations for both the manner of articulating vowels as well as their voice quality - collectively these are represented by multiple diacritics both above and below vowels.
If you'd like to give it a try, the project could use your help. There is a tutorial video to watch first, and then you can jump right into transcribing. You can do just a single page, or as many as you wish.
Reported in Science today, scientists George Church, Yuan Gao and Sriram Kosuri report that they have written a 5.27-megabit "book" in DNA - encoding far more digital data in DNA than has ever been achieved.
Writing messages in DNA was first demonstrated in 1988, and the largest amount of data written in DNA previously was 7,920 bits. The challenge in writing more information than this has been creating long perfect sequences. The current project uses shorter sequences, each encoding 96-bit data block, along with a 19-bit address that specifies the location of the data block within the larger data set. Then redundancy reduces errors: each base only encodes a single bit (A and C are both "0", G and T are both "one"), and each data block has several molecular copies.
DNA has several advantages for archival data storage - information density, energy efficiency, and stability. With regard to stability DNA offers readability "despite degradation in non-ideal conditions over millennia" - by which they mean 400,000 years! (See Church and Regis, in their forthcoming book on the subject.)
If we wish to intentionally use this technology for active long-term information storage (imagine some crucial message we need to convey to the future), we should probably anticipate the possibility of a discontinuity in technological knowledge and access to tools that could read the information. This raises questions of discoverability, decodability, and readability.
Ubiquity aids discoverability - if the information is everywhere it is easier to find, even stumble upon, by accident. Still, clear signals / signposts could aid discovery (neon green cockroaches anyone?). With regard to decodability, I'll simply mention there several layers of encoding to be unraveled here: spoken human language > written language in text form > digital / binary > DNA. And presumably readability requires tools on the order of at least what we have available today, unless you can make the expression of the information obvious in some biological way.
Wonderfully exciting new stuff to conjure with from the perspective of technologies for the Long Now Library. We are also delighted to be working with Dr. George Church to provide Rosetta / PanLex data that may be written in a new "edition" of the DNA book, so check back for updates!
This weekend, the New York Times published an article about the extremely endangered Silitz Dee-ni language - an Athabaskan language spoken in the coastal Northwestern United States. It is striking that this is not a story of last-speaker language death - such stories are of course highly newsworthy, but also quite depressing from the vantage point of those working to preserve global linguistic diversity. Instead here is a story of linguistic and cultural restoration and revival, and the incredible efforts of a few people that are bringing it about. We are increasingly seeing such stories in mainstream media, and it is encouraging.
At the core of the Silitz Dee-ni language revitalization project is the creation of a now 10,000+ word dictionary, assembled over the course of many years, from materials and recordings created by tribal members as well as those compiled by linguists over the past century, now housed in many different language archives and university library special collections. Bud Lane, one of the main dictionary developers has recorded most of the 10,000 entries himself.
For several years, the dictionary database was maintained off-line and password protected so that only tribal members could access it. Recently, however, the project team decided to create an open online version - a "talking dictionary" - that has significantly raised the profile of the dictionary team's efforts, the language itself on a global stage, as well as highlighting the value the language has to the Silitz people.
You can explore the talking dictionary through its Silitz Dee-ni / English search interface. Some default searches produce some extensive results, some with pictures as well as sound - for example "basket" or "salmon" or a basic verb like "put" that illustrates the internal complexity of words that Athabaskan languages are famous for.
It is often said by lexicographers that a dictionary is never finished - this is partly because the task of compiling them is gargantuan, but also because a healthy language is always changing. Some words become obsolete, falling into disuse, while other novel words emerge as speakers name and talk about new entities in their world. For a language that has gone through a period of obsolescence, many new words need to be created to name and talk about the modern world. At this point, the Silitz appear to be focusing on compiling all of the vocabularies available to them, but with language expansion being a primary goal, one can imagine a future effort devoted to vocabulary creation.
[N.B. the interface and database designer for the Silitz Talking Dictionary project is former Rosetta Project intern Jeremy Fahringer, now at Swarthmore College ITS. Well done, Jeremy!]
The Rosetta Project was created to begin the work of filling Long Now’s 10,000 Year Library and in 02011 student filmmaker Scott Oller offered to help tell the story of the project’s aspirations and achievements. This short documentary, Oller's senior thesis, was shot over the course of several weeks in the Spring of 02012 and explores the contents of the Rosetta Project’s collection of linguistic data, the Internet Archive’s role in hosting and making accessible that data, and the aesthetics and functionality of the Rosetta Disk itself.
The Rosetta Project and PanLex Project at The Long Now Foundation are excited to announce that we are participating in a new initiative called the Endangered Languages Project, which is backed by the Alliance for Linguistic Diversity.
As member organization of the Alliance, we will be providing support for the Project, which aims to:
accelerate, strengthen, and catalyze efforts around endangered language documentation,
support communities engaged in protecting or revitalizing their languages, and
raise awareness about ways to address threats to endangered languages.
Through the Endangered Languages Project, endangered language communities and scholars are able to contribute their own materials by uploading language documentation via Google tools such as Google Docs and YouTube. Alliance members will help maintain the project as an open space so that any user can find, share, and discuss the most comprehensive and up to date information and primary data on endangered languages.
As part of our contribution, the PanLex project has offered to make accessible its compilation of a half-billion pairwise translations among 17 million lexemes in 6,000 languages. Our hope is that this data can be made available through the Endangered Languages Project to promote collaboration with researchers and enable more than a trillion additional inferred lexical translations.
For those in the San Francisco area looking for a great Friday night out, the San Francisco Center for the Book is opening a new exhibit tonight, "Exploding the Codex, Theater of the Book" which includes a Rosetta Disk. The event runs from 6:00 to 8:00 pm at the San Francisco Center for the Book, 300 De Haro Street and is free and open to the public. The Exhibit runs through August 31 in the Austin Burch Gallery.
On July 9, Rosetta Project director Laura Welcher will be giving a talk in the Long Now museum on "Bringing the World's ~ 7,000 Languages Online." This talk is part of an ongoing series offered by SF Globalization, a San Francisco meetup group interested in software localization and internationalization.
"There are nearly 7,000 languages spoken in the world today, but the vast majority of them are contracting dramatically in use, rapidly approaching obsolescence and extinction. While computers, mobile devices and the Internet could offer an entirely new domain of language use – infusing these languages with modern vitality and vigor – there are few languages that can be used with ease in this domain today. In this talk, Dr. Laura Welcher will present the work of The Rosetta Project that she directs at The Long Now Foundation, their efforts to build resources and capacity for all human languages, and what it takes to bring these languages online."
Find all the details and RSVP to attend on the Meetup Page.
This summer, the Rosetta Project is working on a series of Record-a-thon events. While previous Record-a-thons have collected recordings from many languages at once, the Record-a-thon events planned this summer are focused on specific languages. The aim is to capture, through video recording, spoken language samples from a number of speakers. We aim to record small groups of speakers for each language we record, with at least 2 hours of recording for each language.
The Record-a-thon events that will be taking place this summer will collect many hours of video and audio linguistic data. While this is certainly valuable information, it would be much more useful for future research if it were in an easily searchable format. Generally, as the amount of information becomes greater, it becomes less possible for a human to get anything out of that information. This is, of course, the problem of the information age.
With the advent of modern recording techniques, this is also a large problem for speech scientists and speech technologists. A common way of formatting audio data is to segment the speech, which is continuous (no pauses between sounds or words), into speech sounds (phonemes) and to label them (eg, the second sound in the word Rosetta would be labeled 'o', and would be marked as occurring from the end of the 'r' sound to the beginning of the 'z' sound). Having myself segmented and labeled speech sounds, I can attest that is an extremely laborious process. To have data that is already formatted, processed, and ready for analysis is an enormous boon.
Recordings of spoken language have tremendous value, but are not always immediately useful for those who would have the greatest interest in the data. It is my hope to make the data collected this summer immediately useful to researchers, both in the academic world and in industry. In particular, I am interested in creating an audio corpus (body of data) for each language recorded, ideally which will be divided into individual speech sounds (segmented), with each sound labeled. This type of corpus is called an aligned speech corpus. Recently, there have been attempts to automate this process, letting a computer segment the speech sounds. This greatly reduces the amount of time needed to turn raw speech data into formatted, more immediately useful data.
Who exactly is interested in spoken language data? I previously mentioned phoneticians. Unlike Professor Henry Higgins in the movie My Fair Lady, today's phoneticians are interested in the question of how language is actually spoken rather than how it is supposed to be spoken. One question a phonetician might be interested in, is whether vowels are longer at the end of a word than at the beginning. Generally, English-speakers don't think of speech sounds as being longer or shorter, but in fact different sounds differ from one another in length, and even the same speech sound may vary depending on its location in a word. This kind of question is answerable by looking at spoken data that has the beginnings and ends of sounds marked (segmented), and the sounds themselves labeled.
Speech and hearing scientists could also find value in speech data that has been segmented and labeled. Speech and hearing science has the goal of identifying and treating language disorders. But in order to do this, one must have examples of "normal" language. How is language normally spoken? What is a sign of a disorder, vs normal variation within the language? Having many examples of a language, from different speakers, would be helpful for answering this question.
Finally, the language technology community could also find labeled and segmented speech data extremely useful. Babies are not born knowing a particular language, but require continuous exposure to a particular language in order to learn it. An automatic speech recognition system is the same; it needs to be trained in a particular language in order for it to recognize words, phrases, and sentences in that language. Many speech recognition systems are trained on aligned speech corpora.
Several aligned speech corpora exist for English. What would be especially valuable about creating aligned corpora from data collected this summer is that the languages we anticipate collecting are not the extremely well-studied, more common languages. Having corpora for these languages provides wider access to them. A researcher in Tucson (where I live) might struggle to find 10 speakers of Latvian, but could have access to a substantial spoken Latvian corpus with access to the internet. Further, having a corpus that is already labeled would allow the researcher to have a much larger quantity of usable data than is collectible by a single person, at least within a reasonable time-frame. Having data for less common languages allows for a better understanding of language in general, better understanding and diagnosis of language disorders, and the expansion of speech technologies to new populations.
The Rosetta Project was just featured in the radio show "Lingua Franca," presented by Maria Zijlstra and broadcast on ABC Radio National Australia. The full program is available here as a podcast on the Lingua Franca website.
While globalization is usually considered a primary factor in language endangerment, global economies also provide access to inexpensive communication technologies like the internet and mobile devices - and these technologies are increasingly enlisted as tools to increase the use of endangered languages, as reported recently in the BBC News.
Many endangered language speech communities are gravitating towards Twitter, as well as social media services like Facebook, to promote language use and language learning. For children especially, the ability to use their heritage language with these ubiquitous social media sites provides an essential "coolness" factor, giving their languages relevance and an important new domain of use in the modern world.
Those who use smaller languages on public sites like blogs, or Twitter, are creating an additional resource that they are probably unaware of: the language that they craft and post helps build a text corpus for their language that can pave the way for better tools to enhance that language's use online.
Dr. Kevin Scannell, a computer scientist, mathematician and endangered language speaker, has created a multilingual web crawler called An Crúbadán (which literally means "crawler" in Irish). The crawler identifies and computes the probability of 3-character sequences, which provide a unique "fingerprint" for any given written language. Here is an image showing the catch he netted with a recent trawl: over 1,000 different languages being used online (click on the image below for more information):
According to Scannell, the identified ever-growing corpora provide a means "to develop basic resources that help people use their language online: keyboard input methods, spell checkers, online dictionaries, and so on." In his other research, he has developed crawlers that explicitly capture endangered language Tweets (Indigenous Tweets) as well as blogs (Indigenous Blogs) which he says "aim to strengthen languages through social media."
The September 02011 issue of the journal Language included an article entitled “A Cross-Language Perspective on Speech Information Rate,” by a team of linguists working with the University of Lyon and the French National Center for Scientific Research. Like many linguistic studies, this one investigates the parameters of human language and seeks to identify commonalities that hold true across languages. Given, however, that universal grammatical rules have proven more difficult to define than linguists might have hoped, this study was designed to test the universality of a different factor - time.
The authors hypothesize that “a trade-off is operating between a syllable-based average information density and the rate of transmission of syllables in human communication.” Basically, a language that is spoken quickly - in terms of syllables per second - uses more syllables than one that is spoken slowly in order to say the same thing.
To test their hypothesis they analyzed audio recordings of native speakers of seven different languages reading brief texts written in various styles. There were twenty texts, each composed in English and translated into the other languages. The authors compared the number of syllables that each language used in a given text, as well as the amount of time taken by speakers of different languages to actually say the entire texts. And indeed, they found that for the most part the languages whose texts used more syllables were spoken faster, and vice versa, resulting in equivalent rates of information output. Two complementary strategies for encoding and transmitting ideas.
"One has to consider the [...] loose hypothesis that [the information rate of the language] varies within a range of values that guarantee efficient communication, fast enough to convey useful information and slow enough to limit the communication cost (in its articulatory, perceptual, and cognitive dimensions)."
The premise here is that each translation of each of the texts communicates all of the information communicated in each other translation, adding and subtracting nothing, simply encoding the information according to the rules of each language. It would be interesting to discuss this premise with respect to the notion of linguistic relativity, which argues that your native language actually influences the way you perceive reality. Or in terms of issues such as evidentials or honorifics, which can require that certain information - and therefore more syllables - be included in a statement which in another language might be superfluous. Further research might also be able to analyze across more language families. The seven languages used in this study were English, German, French, Spanish, Italian, Mandarin Chinese and Japanese.
The authors also noted that the syllables themselves in quickly spoken languages are on average less complex, in that they are composed of fewer sounds (i.e. ‘law’ vs. ‘claw’ - both one syllable, but with different numbers of phonemes). As an initial investigation into the speed with which people communicate through speech, this is a fascinating study.
It seems that humans may be naturally and universally self-regulating when it comes to communicating through speech. There is a balance that cannot be disturbed: fast syllables are not allowed to carry too much meaning, and syllables with lots of information must be spoken slowly.
PanLex, the newest project under the umbrella of The Long Now Foundation, has an ambitious plan: to create a database of all the words of all of the world's languages. The plan is not merely to collect and store them, but to link them together so that any word in any language can be translated into a word with the same sense in any other language. Think of it as a multilingual translating dictionary on steroids.
You may wonder how this is different from some of the other popular translation tools out there. The more ambitious tools, such as Babelfish and Google Translate, try to translate sentences, while the more modest tools, such as Global Glossary, Glosbe, and Logos, limit their scope to individual words. PanLex belongs to the second, words-only, group, but is far more inclusive. While Google Translate covers 64 languages and Logos almost 200 languages, PanLex is edging close to 7,000 languages. With the knowledge stored in PanLex, translations can be produced extending beyond those found in any dictionary.
Here’s an example to give the basic idea of how it works. Say you want to translate the Swahili word ‘nyumba’ (house) into Kyrgyz (a Central Asian language with about 3 million speakers). You’re unlikely to find a Swahili–Kyrgyz dictionary; if you look up ‘nyumba’ in PanLex you’ll find that even among its half a billion direct (attested) translations there isn’t any from this Swahili word into Kyrgyz. So you ask PanLex for indirect translations. PanLex reveals translations of ‘nyumba’ that, in turn, have four different Kyrgyz translations. Three of these (‘башкы уяча’, ‘үй барак’, and ‘байт’) each have only one or two links to ‘nyumba’. But a fourth Kyrgyz word, ‘үй’, is linked to ‘nyumba’ by 45 different intermediary translations. You look them over and conclude that ‘үй’ is the most credible answer.
How confident can you be of your inferred translation—that Swahili ‘nyumba’ can be translated into Kyrgyz ‘үй’? After all, anyone who has played the game of “translation telephone” (where you start with Language A, translate into Language B, go from there to Language C and then translate back to Language A) will know this kind of circular translation can result in hilarious mismatches. But PanLex is designed to overcome “semantic drift” by allowing multiple intermediary languages. Paths from ‘nyumba’ to ‘үй’, for example, run through diverse languages from Azerbaijani to Vietnamese. Based on such multiple translation paths, translation engines can provide ranked “best fit” translations. As the database grows, especially in its coverage of “long tail” languages, possible translation paths will multiply, boosting reliability.
There are a couple of demonstrations that you can try with a browser. This will give you a sense of the magnitude of the data and the potential power of the database as a tool. One of these is TeraDict. If you enter a common English word like ‘house’ or ‘love’ you are likely to get translations into hundreds, or even thousands, of languages, and in some cases many translations per language. French, for example, has 25 translations for ‘house’ and 55 translations of ‘love’, including ‘zéro’ (hint: Think tennis!). Two similar interfaces allow you to explore the database in either Esperanto—InterVorto—or Turkish—TümSöz.
The second web tool, PanLem, is considerably more complicated and is used mostly by PanLex developers to enlarge and evaluate the database. But it’s publicly accessible. There is a step-by-step "cheat sheet" to help you climb the learning curve.
PanLex is an ongoing research project, with most of its growth yet to come, but the database already documents 17 million expressions and 500 million direct translations, from which billions of additional translations can be inferred.
PanLex is being built using data from about 3,600 bilingual and multilingual dictionaries, most in electronic form. The process of ingesting data into the database involves substantial curation and standardization by PanLex editors to ensure data quality. The next stage of collection will likely involve dictionaries that exist only in print form. It is hard to say how many are out there, but we expect it is on the order of tens of thousands. It is likely that most of these have not been scanned or digitized. Once they are, there will be a significant effort to improve the optical character recognition (OCR) for these materials—an effort which is likely to be highly informative to the development of OCR technology, since it will involve the human identification of many forms of many different scripts for languages around the world.
PanLex is working closely with the Rosetta Project. PanLex is a wonderful realization of the Rosetta Project’s original goal in building a massive, and massively parallel, lexical collection for all of the world’s languages.
The Berkeley Language Center will be hosting a talk by Long Now’s Dr. Laura Welcher on November 9th. The talk is open to the public and starts at 3:00pm in Dwinelle Hall B-4.
The Rosetta Project at The Long Now Foundation is working to build an open public digital collection of all human language as well as an analog backup that can last for thousands of years–The Rosetta Disk. In the “long now,” the goal is long-term storage and access to information–on the scale that both supports and transcends individual human societies and civilizations. In the “here and now,” the project serves to support and amplify the importance of the world’s nearly 7,000 human languages, the vast majority of which are endangered and, if current trends continue, likely to go extinct in the next 100 years. I’ll present our current work on the Rosetta Project Collection and Disk as well as some new initiatives including the “Language Commons” where we are working to help build the multilingual Web.
There will be a reception afterwards; come say Hello.
With thousands of languages and writing systems used all over the world, making computers and the web widely accessible has taken a herculean effort, with much yet to be done.
One of the main tools used in the expansion of the web’s global reach is Unicode - a database of over 193,000 characters from 93 different writing systems and the standards for using and representing them.
Unicode is maintained by The Unicode Consortium, which sponsors a conference each year to share knowledge and discuss the future of Unicode.
The Rosetta Project shares the Unicode vision of a world where people can use communication technology on their own terms - in their own language.
According to World Internet Statistics, over 80% of all web communication is in about ten languages, with over half in either English or Chinese. The remaining 20% represent "everyone else" including about 400 languages with speaker populations above 1 million, which collectively comprise about 95% of everyone on earth.
Because of essential technologies like Unicode, we are poised to see this breadth of human languages flourish online and on mobile devices, providing for these languages a critical new domain of language use in the modern world. I will present several efforts underway at The Rosetta Project including the "Language Commons" that rely on Unicode as an essential technology in building the multilingual Web.
On July 30, 02011 The Rosetta Project partnered with Mightyverse.com to hold the first human language Record-a-thon at the Internet Archive. This is an event we developed to test the idea that with a few basic guidelines, anyone can use common video devices to help document human language.
The idea is that by creating a 5-10 minute unedited video, and providing basic information about it - essentially just saying what language you think it is in - and then uploading it to the Rosetta Project collection in the Internet Archive, you are helping build a corpus of valuable data for that language. You don't need to be a specialist, and by archiving it you create a resource that others can build on, for many different useful purposes - from language learning and teaching, to linguistic analysis, to building the tools that enable a language to be used with modern technology.
This introductory talk by Dr. Laura Welcher, made the morning of the event, describes the ideas behind the creation of the Record-a-thon:
In the course of a single day, both in-person and remote partipants combined created about 85 videos in 34 different languages. There were speakers of all ages, native and non-native, some quite fluent while others were learners practicing their skills. All the videos they created are interesting to watch and are available here in the Rosetta Project video collection. They recorded conversations, told stories, histories, and jokes, recited poems, and sang lullabies. Here is a sampling (click on the images to see the videos):
Chihota speaking his native Shona. Shona is a language of Zimbabwe with about 11 million speakers. Chihota took home one of the Record-a-thon prizes, having made recordings of himself speaking Shona, Swahili, Sheng (an emergent Swahili-English mixed language) and Chilapalapa (a pidgin that emerged in the mines of South Africa). He also speaks fluent English and Russian. Chihota was unsure that we would consider all of these languages but we assured him we were interested in them all:
Arturo Avila speaking his native Mixteco Bajo from Oaxaca, Mexico. Mixtec languages comprise a cluster of about 50 related languages in Mexico, having anywhere from a few hundred to a few thousand speakers each. Mr. Avila was the lucky Record-a-thon raffle winner of an iPad 2 (participants were given raffle tickets for each recording they uploaded, and Mr. Avila upload a bunch!):
Anita Suter speaking her native language Swiss German, in the Ostschweizer dialect. Standard German is one of the official languages of Switzerland, along with French, Italian and Romansch. Swiss German, with approximately 6.5 million speakers is the spoken variety of German used daily in Switzerland, and it has many dialects, many of which are unintelligible with each other. These dialects are used alongside Standard German, a spoken and written variety which is reserved for more official purposes, in a peaceful linguistic co-habitation known as 'diglossia':
Jordan Brown speaking Yiddish, a language he is studying. Several of the Record-a-thon participants made recordings in languages they are learning or studying. Mr. Brown, a linguistics student and Rosetta Project summer intern, made recordings in both Yiddish as well as in the unrelated Sri Lankan language Sinhala. Here he reads from the Yiddish translation of "Winnie the Pooh" by A.A. Milne. Yiddish is a Germanic language with about 2 million first language speakers and 11 million second language speakers in Israel, Germany, and worldwide:
During the Record-a-thon there were also several Mightyverse Phrase Farm recording stations set up and running all day, where participants could record vocabulary lists, as well as the Universal Declaration of Human Rights. These video files are more complex, but as soon as the files are processed, we hope to make them available at the Internet Archive as well:
"
Other highlights of the day included a keynote speaker by Dr. Elizabeth Lindsey. Dr. Lindsey is an Explorer at the National Geographic, and she inspired us with stories of her experiences on her current expedition to visit and document traditional knowledge-keepers around the world.
Thanks to all of our participants, and to our sponsors The Internet Archive, The Levenger Foundation and Levenger.com, The Long Now Foundation, and to our team of dedicated Rosetta Project Interns and volunteers, without all of whom this event would not have been possible.
The Rosetta Project's newest addition to its online database is set of language recordings assembled by the famous ethnomusicologist Alan Lomax. This collection encompasses approximately 600 recordings of dozens of languages from around the world. The recordings were made primarily in the 60's and 70's by Alan Lomax and by linguists around the world to serve as raw material in Lomax's Parlametrics project, a "comparative study of conversational style." [1] Recordings include children singing in Puluwatese, family conversations in Telegu and stories and songs in Woleaian.
Though Lomax made some of the recordings himself , notably many of the ones made in the USSR, Italy and England, the rest were made by linguists around the world who helped Lomax by sending him tapes of their own field recordings. As Lomax had requested, the recordings consist mostly of five minute long snippets of conversation in various languages along with some telling of stories myths and singing of songs. Through a collaboration with the Association for Cultural Equity, the recordings were loaned to the Rosetta Project with the stipulation that the recordings be digitized. In 2005, Rosetta intern JD Ross Leahy digitized the vast majority of the recordings, approximately 270 reel-to-reel and cassette tapes, and the originals were sent to the Library of Congress for long term archiving. In 2011, Rosetta intern Summer Dougherty transcribed notes, inventoried, organized, and prepared the digital material for upload and in July 2011 the recordings were uploaded to the Internet Archive.
Ethnomusicologist and activist Alan Lomax is famous for his recordings of blues legends including Lead Belly, jazz musicians including Jelly Roll Morton and folk singers including Woody Guthrie. [2]
As a teenager, Lomax started helping his father, folklorist and musicologist John Lomax, collect folk songs. Lomax and his father partnered with the Library of Congress and by 1930, when Alan was 15, they had already contributed over 3,000 recordings to the library's collection. [3] Lomax's role as a microphone for under appreciated and marginalized folk singers brought folk music back into the attention of the public and spurred the folk revival in America, inspiring a new generation of artists, including Bob Dylan. Even British music was affected by Lomax: the Rolling Stones take their name from one of Muddy Waters' songs. [4] Even more recently, Lomax's recording of James Carter and other prisoners singing "Po' Lazarus" was used in the film "O Brother, Where Art Thou?". Other songs have been featured in “The Gangs of New York” and “Moby’s Play”. [5]
Lomax felt that folk music is vital expression of culture, and culture was very important to him. He believed in what he called "cultural equity", "the idea that the expressive traditions of all local and ethnic cultures should be equally valued as representative of the multiple forms of human adaptation on earth." [6] In fact, "his desire to document, preserve, recognize, and foster the distinctive voices of oral tradition led him to establish the Association for Cultural Equity (ACE), based in New York City and now directed by his daughter, Anna Lomax Wood." [7] "After 1960 he devoted himself to comparative research on world music and dance with collaborators from musicology, anthropology, dance, and linguistics." [8] These projects included his study of song, Choreometrics, of dance, Cantometrics and of speech, Parlametrics.
Join us for the Record-a-thon this Saturday July 30 at the Internet Archive and help document and promote the languages used in your own community! We need your help to meet our goal of recording 50 languages in a single day! How many languages can you help us document? Bring yourself and your multilingual friends and be the stars of your own grassroots language documentation project!
Keynote Speaker: Dr. Elisabeth Lindsey, National Geographic
(Tickets are free - your RSVP will allow us to prepare for numbers to expect and what equipment is going to be present, whether you intend to come in person or if you’re participating remotely.)
There is something you can do to help document and promote the languages used in your own community! We need your help to meet our goal of recording 50 languages in a single day! How many languages can you help us document? Bring yourself and your multilingual friends and be the stars of your own grassroots language documentation project!
Professional linguists and videographers will be on site to document you and your friends speaking word lists, reading texts, and telling stories. You can also document your language using tools you probably have in your purse or back pocket — a mobile phone, digital camera, or laptop — just bring your device and our team will guide you through the documentation process.
How do your words and stories make a difference? An important part of language documentation is building a corpus — creating collections of vocabulary words, as well as conversations and stories that demonstrate language in use. From a corpus, linguists and speech technologists can build grammars, dictionaries, and tools that enable a language to be used online. The bigger the corpus, the better the tools!
The recordings you make during the event will be added to The Rosetta Project's open collection of all human language in The Internet Archive. And, you can compete for cool prizes, including an iPad 2 for the participant who records and uploads the most languages during the event!
Please RSVP below and let us know if you plan to attend, and what language or languages you are thinking of recording. Can't make it to the Record-a-thon? Join us online the day of the event for the virtual Record-a-thon, where you'll be able to interact with event staff, monitor event progress, listen live to lectures and talks, and submit your own recordings remotely.
We will be in touch soon with more information about the day's events, and how you can participate! For questions or more information please contact rosetta@longnow.org.
Ellen Bialystok, a research professor of psychology at York University in Toronto, claims a polyglot child develops cognitive efficiency from constantly speaking more than one language: "[t]he constant necessity to resist attending to a second language in favor of the one in use, and the need to switch between languages demands more effortful attention than does monolingual speech production, and this greater cognitive demand fosters the development of a higher level of attentional control." [1]
This affect appears to help stave off the symptoms of Alzheimers. In Bialystok’s study individuals with Alzheimers who had equal levels of outward symptoms were compared. The study essentially shows that people who regularly speak more than one language can perform certain cognitive tasks with significantly less amount of functioning brain matter than can someone who only speaks one language. It seems that bilingualism delays the onset of outward symptoms associated with Alzheimers; provided everything else is equal, those who have the disease and are bilingual will still suffer from brain deterioration, but their symptoms will be less severe. In this sense, bilingualism serves some protection against the effects of Alzheimers.
In a recent New York Times article about her research Bialystok explains, "[t]here’s a system in your brain, the executive control system. It’s a general manager. Its job is to keep you focused on what is relevant, while ignoring distractions. It’s what makes it possible for you to hold two different things in your mind at one time and switch between them. If you have two languages and you use them regularly, the way the brain’s networks work is that every time you speak, both languages pop up and the executive control system has to sort through everything and attend to what’s relevant in the moment. Therefore the bilinguals use that system more, and it’s that regular use that makes that system more efficient."
The claim that bilingualism can actually be advantageous is significant, because in the past bilingualism was generally regarded as a liability. Bialystok notes, "until about the 1960s, the conventional wisdom was that bilingualism was a disadvantage. Some of this was xenophobia. Thanks to science, we now know that the opposite is true." [2] Bialystok describes questions posed to her about which language should be taught to children whose parents speak more than one language, “People e-mail me and say, “I’m getting married to someone from another culture, what should we do with the children?” I always say, “You’re sitting on a potential gift.”
[1] Schweizer TA, et al., Bilingualism as a contributor to cognitive reserve: Evidence From brain atrophy in Alzheimer's disease, Cortex (2011), doi:10.1016/j.cortex.2011.04.009 (available at [www.sciencedirect.com](http://www.sciencedirect.com "Science Direct"))
The author of this post, Colin Farlow, is a 02011 summer intern with the Rosetta Project. He recently graduated from Indiana University, where he studied East Asian Languages and Cultures and Philosophy.
Busuu, a language of Cameroon, is reported to have only eight speakers left in the world.
Speakers of Busuu have nearly all shifted to using another local language Jukun, which has about 2,500 speakers. Jukun and Busuu are related, but are only partially intelligible with each other. Jukun is used by Busuu speakers for almost all purposes, Busuu generally being reserved for use only at Busuu reunions, and only by adults - no children are learning the language. For all intents and purposes, Busuu appears to be a lost cause, destined to disappear from use with the passing of its current generation of speakers.
Yet despite this (or perhaps because of this) it has been adopted as a cause by the eponymous language learning website busuu.com, and awareness of the language’s plight is being spread through the medium of a professionally-produced video with a catchy song featuring the few remaining (but all apparently charming and good-humored) Busuu speakers. The Busuu.com website encourages people to spread awareness about Busuu through Facebook, Twitter and e-cards by sending recorded greetings from each of the remaining speakers. A clever and unusual tactic in raising the profile of an endangered language - but is increased awareness among online social networks likely to translate into increased use within the Busuu heritage speech community?
There are in fact a few notable cases where languages in rapid decline have been reversed, and threatened languages have significantly expanded in use and numbers of speakers - among these are Catalan, and Welsh and Hawaiian. For languages that have only a few remaining speakers like Busuu, Leanne Hinton, a linguist who works with critically endangered languages of Native California in the United States, has devised a technique whereby speakers and learners can create their own immersion environments for language learning. [1] These speakers then teach others the language, including their children. In this way a language can be passed along on a very localized level to a new generation.
To bring a language back into more widespread – even national – use, the key factor is support from every direction possible – top down from the government; bottom up from local communities. [2] Everyone needs to be invested, from governor to grandma, and real world-benefits to potential speakers is key. [3] So if this effort by busuu.com to raise social awareness is effective, and generates broad recognition for the Busuu speech community, the resulting increase of local prestige for the Busuu Language could be significant indeed.
We're certainly willing to give it a try - Busuu Busuu!
[1] Hinton, Leanne. 2002. How to Keep Your Language Alive. Heyday Books.
[2] Crystal, David. 2000. Language Death. Cambridge University Press.
[3] Fishman, J.A. (ed.) 2001. Can Threatened Languages Be Saved? Reversing Language Shift, Revisited: A 21st Century Perspective. Clevedon: Multilingual Matters.
The author of this post, Harry Willoughby, is a 02011 summer intern with the Rosetta Project. He recently graduated from the University of Wales with a degree in Linguistics.
In a new study published in the journal Language and Cognition “When Time is Not Space,” a team of researchers from University of Portsmouth and Federal University of Rondonia claim that the Amondawa, a small Amazonian tribe, speak a language with a very uncommon conceptualization of time. The story was recently picked up by BBC, revealing that the debate about whether language influences thought is very much alive and newsworthy.
According to researchers Sinha et al., the Amondawa have no words for talking abstractly about time (as in the English word 'time'), or time periods (like 'year'):
“What we don't find is a notion of time as being independent of the events which are occurring; they don't have a notion of time which is something the events occur in.”
The mapping of time to physical space is commonly found in human language, and its absence in Amondawa is perhaps the most surprising result of the study. Rather than having a time-space metaphor, the Amondawa conceptualization of time is based on “social activity, kinship and ecological regularity.”
Pierre Pica, a theoretical linguist at France’s National Centre for Scientific Research, question the conclusions derived from this new research. Pica explains that just because Amondawa does not use cardinal chronology, does not mean they view themselves advancing through time any differently than the rest of us who use a cardinal chronological system.
Sinha et al. state that the tribe’s language in no way affects their cognitive ability to grasp temporal concepts -- they talk about events, and sequences of events, and learn Portuguese which does have abstract time expressions. Rather, the Amondawa language provides a different way of construing and talking about temporal concepts in daily life.
This contention about whether the Amondawa language affects its speakers’ thought processes hearkens back to a famous study by Benjamin Lee Whorf on the Hopi Language in the first half of the 20th century. This study was a foundational example for Whorf’s “linguistic relativity hypothesis” – the idea that the language you speak influences the way you think. From his study of Hopi, Whorf concluded:
“The Hopi language is seen to contain no words, grammatical forms, constructions or expressions that refer directly to what we call TIME, or to past, present or future, or to enduring or lasting…the Hopi language contains no reference to TIME, either explicit or implicit.” [1]
Whorf’s ideas about Hopi have received a great deal of criticism over the years, and his data was critiqued as erroneous evidence resulting from deficient research practices. [2] Nevertheless, the idea that language influences thought has certainly stuck around, and is now being raised by a new generation of researchers like Sinha et al who are gathering new data from small and threatened languages around the world.
For more on the relationship of language and thought, listen to our podcasts of previous Long Now seminars by Lera Boroditsky as well as Daniel Everett who talks about Pirahã, a language also from the Amazon.
[1] Whorf, Benjamin Lee. 1950. An American Indian Model of the Universe. The
International Journal of American Linguistics 16(2).
[2] In an interview by BBC, Guy Deutscher explains his ideas about language and thought in addition to describing Benjamin Whorf’s research on Hopi Language.
The author of this post, Colin Farlow, is a 02011 summer intern with the Rosetta Project. He recently graduated from Indiana University, where he studied East Asian Languages and Cultures and Philosophy.
How does human language work? What are its possibilities and limitations? Where did it come from? Many linguists have asked these questions and made contributions to our understanding of language, but how do they get their answers?
One approach is to go out and document a language, which can then be compared to other languages, writings from the past, etc. Through various methods, linguists have succeeded in discovering patterns within and between languages that allow us to define some of their parameters and to organize them into families. But, as two recent publications demonstrate, our ability to recognize patterns—and their underlying causes—may be dramatically increasing with the development of technology that can centralize, organize and manipulate enormous amounts of information.
The two studies were highlighted in The Economist, and both of them offer conclusions that are likely to spark lively debate. Dr. Michael Dunn, from the Netherlands’ Max Planck Institute for Psycholinguistics, published a paper in Nature magazine addressing word-order dependencies—the idea that, for example, if a given language places verbs before objects (eat lunch) it will also place prepositions before nouns (at home). By comparing different languages, linguists have found that there are some strong consistencies in these dependencies, indicating that they are the result of “underlying cognitive or systems biases.” Dr. Dunn, however, has used large databases of basic vocabularies and statistical methods borrowed from evolutionary biology to approach the problem of dependencies in a different way:
To substitute for fossils, and thus reconstruct the ancient branches of the tree as well as the modern-day leaves, Dr Dunn used mathematically informed guesswork. The maths in question is called the Markov chain Monte Carlo (MCMC) method. As its name suggests, this spins the software equivalent of a roulette wheel to generate a random tree, then examines how snugly the branches of that tree fit the modern foliage. It then spins the wheel again, to tweak the first tree ever so slightly, at random. If the new tree is a better fit for the leaves, it is taken as the starting point for the next spin. If not, the process takes a step back to the previous best fit. The wheel whirrs millions of times until such random tweaking has no discernible effect on the outcome.When Dr Dunn fed the languages he had chosen into the MCMC casino, the result was several hundred equally probable family trees. Next, he threw eight grammatical features, all related to word order, into the mix, and ran the game again.
He found that particular word-order traits were not necessarily linked to others in the way that current theories propose. Rather, such dependencies seemed to be ‘lineage-specific,’ suggesting that they have been passed down through language families. “Nurture, in other words, rather than nature,” as The Economist put it.
The other article, published in Science by Dr. Quentin Atkinson of the University of Auckland, also uses statistics and databases in an innovative way. He looked at information from the World Atlas of Language Structures on sounds in different languages and found that phonemic diversity (the number of sounds used in a language) decreases as you follow the pathways of human migration outwards from central/southern Africa. The Science article argues that modern language originated in that part of Africa and that phonemic diversity decreased with every stage of human expansion as small groups of people set off in search of new territory.
Both of these studies utilize phylogenetic language groupings, based on evolutionary theory, and they run statistical analyses with large amounts of data made available by central repositories of linguistic information, such as the World Atlas of Language Structures. The Long Now Foundation’s Rosetta Project is an effort to improve and facilitate that very sort of creative methodology—to organize and make available large amounts of data so that researchers can develop fundamentally new methods of inquiry.
Languages are works of art, great libraries, how-to guides for living on planet Earth, windows into our minds and inalienable human rights. Long Now's own Dr. Laura Welcher, Director of Operations and The Rosetta Project, spoke on March 3rd to a group of Long Now Members about the beauty, variety and value in the almost 7,000 languages spoken in the world. The event was part of our new Salon Series: occasional, intimate talks held in The Long Now Museum & Store for Members of the Foundation.
Laura's talk was called The Rosetta Project and The Language Commons and in it she discussed several efforts to preserve linguistic diversity around the world. The Long Now Foundation's role thus far, she explained, has been to develop and manufacture The Rosetta Disk: a durable, nickel archive of linguistic data. Laura also discussed her work with The Language Commons Working Group - a collaboration of linguists, archivists and programmers working to create an open and accessible encyclopedia of languages and linguistic diversity as a tool for teaching, studying, preserving and sharing languages.
The full audio of Laura's talk can be streamed from the player below or downloaded as an mp3. You can also click through the slides she presented in the window below the audio player.
Two days ago, we learned that a Rosetta Disk made its way into the Special Collections of the University of Colorado Boulder library, and was on public display there. One of our members, Zane Selvans paid a visit, and had an extraordinary experience. He took fantastic pictures and wrote it up on his blog Amateur Earthling - we repost it here with his permission. It is a great illustration of the challenge in keeping information alive over time, place, and people.
In 02008, one of the first prototype Rosetta Disks went to the family of the late Charles Butcher, who was the founder of The Lazy 8 Foundation. Lazy Eight was one of the first supporters of the Long Now 10,000 Year Library and Rosetta Projects...
On January 9, The Rosetta Project presented a poster at the Linguistic Society of America annual meeting, describing a distributed archive model we've developed and implemented with the Rosetta digital collection. Here is a video describing this model, and some of its long-term benefits:
Using data from the Atlas of North American English (ANAE) by William Labov, Sharon Ash, and Charles Boberg combined with his own research, linguist Rick Aschmann created the detailed map above to show regional dialects throughout North America. One of the coolest features is that he's linked over 600 YouTube videos to the map, so that clicking a region will take you to video clips of (mostly famous) people raised in that area so that you can hear a sample of the dialect.
Researchers at Carnegie Mellon have done some similar research, though they're using social media - Twitter specifically - as the data source, rather than just to illustrate linguistic nuance. Jacob Eisenstein and his colleagues looked at 380,000 geo-tagged tweets recently and explored the geographical dialects represented within. They saw differences in the way people abbreviate words to fit the short medium and the slang terms they used in informal messaging and were able to create a statistical model from the variation they saw that could predict the location of a user to within about 300 miles based on the dialect used.
The existence of Twitter and other informal, microblogging platforms affords a newly accessible, low-cost source of data for linguistics researchers since they don't require labor-intensive in-person interviews to uncover patterns of informal speech:
Studies of regional dialects traditionally have been based primarily on oral interviews, Eisenstein said, noting that written communication often is less reflective of regional influences because writing, even in blogs, tends to be formal and thus homogenized. But Twitter offers a new way of studying regional lexicon, he explained, because tweets are informal and conversational. Furthermore, people who tweet using mobile phones have the option of geotagging their messages with GPS coordinates.
Eisenstein also points out that the identifiable regional variation could be an indicator that the internet is less a force for homogenization than often thought.
The Georgetown University Round Table on Languages and Linguistics later this year will explore many ways in which these, "new worlds of words occasion innovative uses of language and new spaces for constructing identities, forming relationships, and expressing social meanings." (GURT 2011)
So, expect to see plenty more research mining social media and remember to act normal online so you don't throw off the results.
Significant amounts of machine-readable data exist for only a few of the 300 languages spoken by nearly 95% of the world’s population. The 300 Languages Project is taking the first steps toward democratizing language technology by collecting parallel text and audio for the rest. You can help us bridge the gap by contributing an audio recording of a simple word list in your language.
If you speak one of the following languages, follow the link, record yourself reading the list out loud (if you don't have recording software, try Audacity), and then email your recording to laine@longnow.org (you can also use a free file-sharing service) or submit it manually to our collection.
Save the Words is a nifty site by the Oxford English Dictionary where lexophiles can adopt an esoteric or obsolete word and revive its use. And get the t-shirt. It would be a fun educational tool in the context of an endangered language, where all of the words need saving.
Join Long Now's Rosetta Project on November 4 from 4 - 7 pm at UCLA's Hammer Museum where we team up with San Francisco-based CRITTER for an Enormous Microscopic Evening. We'll put a Rosetta Disk under the microscope, check out the fine (and finer) print, and maybe hunt for Easter eggs... More information on the evening's lineup from the Hammer Museum:
Enormous Microscopic Evening examines the museum from a microscopic perspective with CRITTER, a San Francisco-based salon dedicated to expanding the relationships between culture and the environment. The evening will focus on demonstrations and workshops about building and manipulating microscopes. Materials and samples taken from around the museum will be examined. Continuing the theme of microscopy, there will be micro performances (short concerts with tiny instruments) and other related events throughout the museum.
Jessie Little Doe Baird, a linguist who has worked for years on reviving the Wampanoag (Wôpanâak) Language, has just been awarded a 02010 MacArthur "Genius" Fellowship in honor of her work and research.
Baird, who is of Wamponoag heritage, studied at MIT under the indigenous language scholar Kenneth Hale. By immersing herself in the language, she has achieved fluency, effectively reviving in herself the spoken use of the long-silent language. Her research is focused on developing a dictionary of Wampanoag, which now includes nearly 10,000 words, as well as language teaching resources, through which she hopes to help usher the language into modern use in the Wampanoag community.
The 300 Languages Project is a special effort by The Rosetta Project to create a parallel text and audio corpus for the world's 300 most widely-spoken languages. We are seeking a limited set of volunteers to test its submission process and offer feedback to its coordinators before the project is globally launched in November. Native speakers of any language (including English) are encouraged to participate.
Swadesh list for the Puoc language in the International Phonetic Alphabet
In the 01950s, American linguist Morris Swadesh, as part of his overarching vision of a quantitative method for determining language relationships on a global and multimillenial scale, developed a set of one hundred words found to be unusually stable across time and language boundaries. Swadesh hypothesized that words like "fire," "moon," "mother" and "bone," common to human experience, were far less likely to change or be substituted with words borrowed from other dialects or languages. The 100 word "Swadesh list" (sometimes up to 207, depending on the variety of the list used) is now widely collected in linguistic field research, and functions as a kind of universal linguistic fossil. With careful study, these lists can reveal ancient language relationships and processes of linguistic change typically obscured by centuries-long processes of evolution and borrowing. As familiar examples, such processes transformed Chaucer's English into modern English and Latin into the modern Romance Languages.
In 02004, The Rosetta Project undertook a National Science Foundation funded project to increase both the size and utility of its long-term multilingual archive and at this time added a large number of Swadesh lists to its collection. Lexical database archivists Tim Usher and Paul Whitehouse contributed original research (Tim Usher's 02002 Indo-Pacific database and Paul Whitehouse's 02002 Australian and New Guinea database were central among the additions) and also brought in outside resources, including Darrell Tryon's Comparative Austronesian Dictionary (01995), George Starostin's Dravidian database, and Ilya Peiros' Mon Khmer database. In many of these cases, as with the Usher and Whitehouse collection, the 100-200 term Swadesh lists were a subset of a larger lexical data collection project. Despite the Swadesh list's limitation in size compared with a resource like a dictionary, a large collection of the same material in many different languages is useful as a parallel dataset for cross-linguistic comparison.
This collection of Swadesh lists was included as a parallel data set among the documents micro-etched on the Rosetta Disk, a physical copy of The Rosetta Project's long-term linguistic archive created in 02008. And for a period of time, the lists were available on The Rosetta Project's website via an interactive tool which allowed visitors to view and compare lexical items in over a thousand languages and also contribute their own lexical data. But as the Rosetta Project site evolved and the structure of serving environments changed, this tool became technologically obsolete. While there was (and remains) no lack of storage space for the lists, there was a critical lack of what Long Now board member Kevin Kelly calls "movage."
"Movage," says Kelly, "means transferring the material to current platforms on a regular basis — that is, before the old platform completely dies, and it becomes hard to do. This movic rhythm of refreshing content should be as smooth as a respiratory cycle — in, out, in, out. Copy, move, copy, move." And it is movage, not storage, says Kelly, that is critical to keeping information alive: "The only way to archive digital information is to keep it moving." In other words, simply storing data isn't enough to ensure its longevity; it must be copied, moved, and made redundant. And not just once or twice — indefinitely. Kurt Bollacker, Long Now Foundation Digital Research Director, adds: "[b]ecause any single piece of digital media tends to have a relatively short lifetime, we will have to make copies far more often than has been historically required of analog media. Like species in nature, a copy of data that is more easily “reproduced” before it dies makes the data more likely to survive." [1]
Since the 02004 iteration of the Swadesh list program, The Rosetta Project has launched a comprehensive migration of all of its data to The Internet Archive, a free online digital library founded in 01996 with over 4 petabytes of storage. The Internet Archive exemplifies the paradigm shift in the field of information preservation from storage to movage: users of the site can upload any document they have permission to distribute to the site for free, where anyone with access to the internet can then download it to their own machine. Thousands of downloads are made every day from Internet Archive servers by users all over the world: early "movage" on a massive scale.
After a long process of unraveling and decoding the Swadesh list data, which had fallen victim to rapid changes in character encoding and database standards, The Rosetta Project has now moved the collection of 1,235 Swadesh lists into The Internet Archive. Recognizing the substantial merit and long-term advantages of the movage model and its successful early implementation by The Internet Archive, our goal is for the lists to have a long, useful, and redundant residence there.
The relocation of the Swadesh lists is also the first step of The Rosetta Project's latest undertaking, The 300 Languages Project. Source materials collected for The 300 Languages Project, whose aim is to address a need for highly-structured linguistic resources in the world's 300 most widely-spoken languages, will be stored at The Internet Archive with the rest of The Rosetta Project collection.
Was the 5-to-6-year period the Swadesh list data spent in the darkness unusual? According to Kelly, not at all: "We don’t know what the natural movage respiration cycle is for digital media yet since it is still very new," says Kelly, "but I suspect the cycle is much shorter than we think. I would guess it is 5 years. No matter what digital format you have your precious [data] stored on, you should expect to move it onto new media in five years — and five years after that forever!"
Egyptian Hieroglyphs on The Rosetta Stone were deciphered by scholars, but a new computer program written at MIT could potentially accomplish the same feat today:
“'Traditionally, decipherment has been viewed as a sort of scholarly detective game, and computers weren't thought to be of much use,’ study co-author and MIT computer science professor Regina Barzilay said in an email.” (quoted in this recent writeup in the National Geographic Daily News).
The language in this case is Ugaritic, written in cuneiform and last used in Syria more than three thousand years ago. Archaeologists discovered Ugaritic texts in 1928, but linguists didn’t finish deciphering them for another four years. The new computer program did it in a couple of hours.
While an exciting and significant first step, the program is not a silver bullet solution to language decipherment. Human beings figured out Ugaritic long before the computer program came along, and it remains to be seen how well the program works with a never-before-deciphered language. Furthermore, the program relied on comparisons between Ugaritic and a known and closely related language, Hebrew. There are some languages with no known close relatives, and in those cases, the computer program would be at a loss.
Of course, we can’t be certain exactly how the technology may progress in the future. But with the Rosetta Disk designed to last for thousands of years, and with hundreds of languages classified in the Ethnologue as nearly extinct, an automated decoder of language documentation seems likely to prove useful eventually. It’s nice to know we’ve made a promising start.
The Rosetta Project is pleased to announce the Parallel Speech Corpus Project, a year-long volunteer-based effort to collect parallel recordings in languages representing at least 95% of the world's speakers. The resulting corpus will include audio recordings in hundreds of languages of the same set of texts, each accompanied by a transcription. This will provide a platform for creating new educational and preservation-oriented tools as well as technologies that may one day allow artificial systems to comprehend, translate, and generate them.
Huge text and speech corpora of varying degrees of structure already exist for many of the most widely spoken languages in the world---English is probably the most extensively documented, followed by other majority languages like Russian, Spanish, and Portuguese. Given some degree of access to these corpora (though many are not publicly accessible), research, education and preservation efforts in the ten languages which represent 50% of the world's speakers (Mandarin, Spanish, English, Hindi, Urdu, Arabic, Bengali, Portuguese, Russian and Japanese) can be relatively well-resourced.
But what about the other half of the world? The next 290 most widely spoken languages account for another 45% of the population, and the remaining 6,500 or so are spoken by only 5%--this latter group representing the "long tail" of human languages:
Equal documentation of all the world's languages is an enormous challenge, especially in light of the tremendous quantity and diversity represented by the long tail. The Parallel Speech Corpus Project will take a first step toward universal documentation of all human languages, with the goal of providing documentation of the top 300 and providing a model that can then be extended out to the long tail. Eventually, researchers, educators and engineers alike should have access to every living human language, creating new opportunities for expanding knowledge and technology alike and helping to preserve our threatened diversity.
This project is made possible through the support and sponsorship of speech technology expert James Baker and will be developed in partnership with his ALLOW initiative. We will be putting out a call for volunteers soon. In the meantime, please contact rosetta@longnow.org with questions or suggestions.
Yurok (YUR) is the language of the Yurok people of northwestern California. As with most indigenous American languages, European contact has mostly come to replace Yurok with English, so that as of 2009 it is near extinction. Yurok belongs to the Algonquian language family, most of whose other members are geographically distant from Yurok. Accordingly, Yurok is surrounded by languages unrelated to it, except for the only distantly related (and extinct) Wiyot.
Yurok has a set of glottalized consonants (sounds produced with the glottis closed, as if holding your breath) that contrast with their nonglottalized counterparts. The glottalized sounds are less common but are important in Yurok morphology, such as verb conjugations.
Some verbs must inflect (be conjugated) for person and number, others cannot, and many can go either way. For example, the word for eating must takedifferent endings according to the subject: nepek’ for ‘I eat,’ nepe’m for ‘you (singular) eat,’ nep’ for ‘s/he eats,’ nepoh for ‘we eat,’ nepu’ for ‘you (plural) eat,’ and nepehl for ‘they eat.' On the other hand, chek ‘sit,’ always maintains the same form no matter who and how many are sitting. Finally, skewok ‘want’ can remain skewok for all subjects, or it can inflect as skewoksimek’ ‘I want,’ skewoksime’m ‘you (singular) want,’ skewoksi’m ‘s/he wants,’ etc., just as the verb ‘eat’ does.
Yurok has no distinct category of adjectives; the words that translate to adjectives or express adjective-like meanings behave like verbs in terms of word order and inflection. For example, there is a word for being big that inflects just as verbs do: peloyek’ ‘I am big,’ peloye’m ‘you are big,’ pelo’y ‘s/he is big,’ etc. Numerals are also a type of verb, and they have different forms according to the type or shape of thing being enumerated (for example, humans versus animals, or flat things versus tufted things).
Ways of writing Yurok have varied over time and remain not entirely settled. In the 1980s the Yurok Language Committee adopted UNIFON, designed (by an economist) as an English pronunciation key. However, UNIFON was impractical and therefore unpopular, and the Yurok Language Committee adopted an alternative system, which was later revised by linguists working on the language (as Leanne Hinton details in her unpublished 2010 article "Orthography Wars"). The Berkeley Yurok Language Project, a searchable collection of Yurok stories, words, and morphemes, lists entries in both the original alternative system and the revised system.
Lakota [1], the language of the Lakota tribe of the Great Plains, is fading before its speakers' eyes. Although Lakota is one of the most robust Native American languages today, its speaker population has fallen far since its peak in pre-colonial times and continues to dwindle. This reflects the experience of many native tribes, and is largely a result of US government policies concerning these peoples. Lakota speakers (the Ethnologue puts their number around 6,300) are left in danger of losing not only their language but the vital cultural information it holds.
Lakota, like most of the world's languages, was not originally written, and much of the long tradition and history of the Lakota exists only orally in their stories and ceremonies. The Lakota people did, however, keep detailed historical records, as can be seen in the "Lakota Winter Counts," now archived online on the website of the Smithsonian National Anthropological Archives. These are pictographic calendars detailing important historical events in the lives of the Lakota.
An alphabetic writing system for the Lakota language in use for the past four decades has now been widely adopted by Lakota speakers. And, in a modern effort to revitalize the Lakota language, the Lakota Language Consortium has compiled textbooks from introductory to college level and an expansive online forum to assist children and adults in learning and thereby preserving the language.
They have also compiled a 20,000-word dictionary of Lakota, including wonderfully complex words like "woímnayankel," which expresses the humbled yet connected feeling one experienced when witnessing something particularly majestic in nature, such as the aurora borealis. Lakota words are often this complex, efficiently expressing ideas that would take a sentences or two in English. Efforts like the Lakota Language Consortium allow the Lakota language to not only survive but flourish, giving future generations the chance to embody and spread the culture of their ancestors.
The Rosetta Project's collection on the Internet Archive has records of the Lakota language in the form of three text excerpts: a description of where Lakota was historically spoken; a phonology, which uses a chart to characterize phonemes by linguistic traits; and an orthography, or explanation of the Lakota writing system.
[1] The Lakota were historically known as the Sioux, but this is an exonym from their Algonquian neighbors to the east, and the term is deprecated today.
Rosetta Project linguists and archivists traveled to Maker Faire this past weekend to demo the Rosetta Disk for a crowd of nearly 80,000 people. We brought the first and second prototypes of the Rosetta Disk, and set up a microscope with a camera to view Disk pages up close. We also had a "Digitization Station" where Maker Faire attendees could watch and participate in the collection of language documentation for the disk.
Would you like to help translate the subtitles of this video? You can here at dotSUB.
"Language is identity," Darfur refugee Daowd I. Salih told the New York Times about a week ago. He was being interviewed for an article called "Listening to (and Saving) the World's Languages." As mentioned in this Rosetta Project blog post, the article discusses the amazing variety of spoken languages in New York City, and what residents are doing (or not doing) to preserve their native language.
One of the languages the article touches on is Ormuri, a language of multiple dialects spoken in small regions of Afghanistan and Pakistan. According to the Ethnologue, Ormuri has only about 1,050 speakers. The New York Times article reveals a plan to canvass New York City for speakers of Ormuri in order to learn more about the language and the cultural information it holds.
Languages with small speaker populations are quickly dying out, and the data they contain (whether it be linguistic, historical, or cultural) is important enough to merit a concerted effort at saving them. Ormuri is a perfect example, especially in the political and economic environment of our time (read: the complex tangle that is our current Middle Eastern relations). The Rosetta Project's database in the Internet Archive contains a detailed description of Ormuri, including a history of its speakers: where they came from, who their ancestors are, and how their language has co-evolved with those around it to become what it is today.
In my mind there is nothing that illustrates a culture's unity so much as its language. It allows people to build social relationships, conduct business transactions, and express to fellow humans everything they hold dear. What's more, as any good anthropologist knows, learning the language of a culture is one of the most important steps an outsider can take to gain the trust and respect of its people.
What does this have to do with an obscure Afghan language, or with Darfur refugees? Only this: if we intend to successfully navigate the conflicts of the modern global world, it is absolutely necessary to understand and relate to the people with whom we intend to work. The Middle East in particular, Afghanistan being an illustrative example, is culturally very foreign to the West; its people have lived for centuries in small, autonomous groups that hold to varied, often contradictory beliefs. The fact that so many of these groups have their own language, like Ormuri, is telling of their relative isolation, and gives clues to how they live their lives.
Rosetta's description of Ormuri tells the story of its peoples' interactions through Ormuri's morphology. By studying the languages Ormuri had contact with and how these influenced its words, we can begin to create a web of social and economic interaction that would show the connections and dissociations between groups in the area. For example, Ormuri has many morphological similarities to Pashto, a common language in the region of Waziristan where Ormuri is spoken. Ormuri pronouns are strikingly similar to their Pashto equivalents, and many scattered words share similarities, like "wife," "glitter," and "to sit down." Pashto has also phonetically influenced Ormuri, replacing some traditional Ormuri allophones with similar Pashto ones.
Ormuri has also sustained contact with Persian, which is evident in many morphological changes that mimic the latter: loss of gendered nouns, simplification of plural nouns, and reduction of irregular past participles. Analyzing this data led the author, Georg Morgenstierne, to doubt the previous belief that Ormuri speakers descend from Kurds, and provided evidence for further theoretical investigations.
The very existence of this kind of knowledge is what Rosetta is all about; by preserving minority languages and stressing their importance, we hope to contribute vital insights into the lives of their speakers, insights that can be put to good use in surprising places. After all, you never know who you'll meet on the New York City subway.
[A note of introduction: this is my first post as an intern with the Rosetta Project. I will be working with Rosetta for three months, building the collection in the Internet Archive and continuing to spotlight Rosetta material on this blog.]
The New York Times ran an article today about endangered languages spoken within the New York City immigrant population - by some estimates as many as 800 languages are represented:
"In addition to dozens of Native American languages, vulnerable foreign languages that researchers say are spoken in New York include Aramaic, Chaldic and Mandaic from the Semitic family; Bukhari (a Bukharian Jewish language, which has more speakers in Queens than in Uzbekistan or Tajikistan); Chamorro (from the Mariana Islands); Irish Gaelic; Kashubian (from Poland); indigenous Mexican languages; Pennsylvania Dutch; Rhaeto-Romanic (spoken in Switzerland); Romany (from the Balkans); and Yiddish."
The article designates New York City as "the most linguistically diverse city in the world." I don't know if that is in fact true, but it seems likely.
For the United States, there is data compiled by the US Census on language use - since 1980, the long form of the census has asked several questions about language use - Does this person speak a language other than English at home? If so, what is this language (fill in the blank)? How well does this person speak English (very well, well, not well, not at all)? Since the long form is distributed to one in ten households, the smaller the group the less accurate the count tends to be. Still, the numbers give some idea, and it is always interesting to see what languages get listed.
For 2008, the US Census compiled data on the languages spoken at home for cities with 100,000 or more people. The column that is especially interesting for endangered languages is the "other languages" category - that is not English or Spanish, not other Indo-European, and not Asian or Pacific. New York City tops this list with 179,000 speakers of other languages (60,000 of whom are dominant in this language). Los Angeles is next with 43,000 speakers of other languages. San Francisco is #32 on the list with 5,700 speakers of other languages.
To make better use of the wealth of linguistic diversity in their own backyard, Daniel Kaufman and colleagues at The City University of New York have started the independent Endangered Language Alliance - "an urban initiative for endangered language research and conservation." This is, in fact, a time honored tradition among linguistic graduate students and faculty who lack time or resources to travel. But judging by the numbers of speakers of small languages in large cities, and the rapid loss of small languages around the world, this kind of program is just plain smart. Having more of them in urban locales - or maybe existing programs like StoryCorps - could use "diaspora sourcing" to make a big impact in the documentation and revitalization of endangered languages.
Last Friday evening, Long Now joined the Global Lives Project in celebrating their world premiere opening at San Francisco's Yerba Buena Center for the Arts. Through a huge volunteer effort, Global Lives has produced ten films - each 24 hours long - that visually capture the everyday life of ten people around the planet. And on Friday we could view them all, at the same time, in the same room. Ten huge screens hung from the ceiling of the Yerba Buena Forum and around a thousand people throughout the evening ambled around and under them, listening as voices emerged -- Kai Lu, from Anren China speaking to his wife in a village dialect of Sichuan Yi, young Edith Kaphuka from Ngwale Village, Malawi code-switching with her friends on the playground between Chichewa and Chiyao, James Bullock of San Francisco chatting up the tourists on his cable car in West Coast American English. Some screens showed people working, others playing, some eating, others sleeping -- a glimpse into one human day on planet earth.
A second ongoing installation in the YBCA Room for Big Ideas provides a more intimate viewing space, with ten partitioned rooms and LCD viewing screens. Each room is furnished with seating for one or two, with walls and floors embellished with fabrics, colors and textures evocative of the region of the film. Kiosks and wall graphics give a bit of background about the project, and the ten participants. And while the installation as a whole gives the sense of a finished, polished project, three computers set up prominently in the room tell a different - and quite wonderful - story.
This is not a finished project - in fact, it is very much a work in progress. One of the greatest ongoing efforts is one that anyone can help with - the subtitling of each film in as many languages as possible (through the crowdsourced subtitling site dotSUB). The first pass was getting all ten films subtitled in English for the opening night, and that effort is still only about 80% done. It is an enormous effort.
Jason Price, one of the producers of the Malawi shoot, tells the story of being nearly at wit's end trying to find anyone to help translate Edith Kaphuka's Chichewa into English -- until someone suggested he set up a Facebook Group, and then 2,500 mostly expatriate Chichewa speakers arrived ready to help (there are, of course, many speakers of Chichewa in Malawi, but the need to access streaming video to do the translations made that nearly impossible).
Through the steadfast effort of about 25 of these people, the full twenty four hours of video has now not only been transcribed and translated, but put thorough about five stages of checking, rechecking and review to ensure its accuracy. And, it is now the largest corpus of spoken transcribed Chichewa on the web. (What might this 'seed' corpus enable down the road? Chichewa online dictionaries? Spell checkers? Natural language processing? Search? This group of translators may, without realizing it, be forging the way for a real Chichewa language online presence.)
For Global Lives, this set of ten videos is just the beginning of a much larger library of human life experience. Not grand experiences, not Hollywood, not Bollywood -- in the words of David Harris, the project's director (responding to the umpteenth activist proposal, this one by yours truly) "we want boring!" Because what we see as the everyday, the mundane, the routine is in fact a picture of our own humanity - and for that each Global Lives shoot is worth a thousand Hollywood productions.
The Global Lives installation in the Room for Big Ideas will be open through June 20, 02010 at San Francisco's Yerba Buena Center for the Arts. The Long Now Foundation sponsored the world premiere installation in the YBCA Forum through a grant from The William and Flora Hewlett Foundation.
This week, the New York Times ran an article about a recent scientific discovery in the predator alert calls of Campbell's monkeys. Strikingly, they seem to have the ability to create complex calls out of multiple elements - a "morphological" (word building) process previously thought to only take place in human language.
Human languages do this all the time - for example the word 'walked' is built of two morphemes, one carrying the main verbal action 'walk' and the other marking past tense '-ed'. In the case of the Campbell's monkey, morphemes are often combined to indicate different types of threats. Previous observations of monkeys have shown that they sometimes use different types of calls for different types of predators, but what's unique about these calls is that some of them can be combined with other calls to change their meaning. So, instead of just having a "jaguar!" call and an "eagle!" call as has been observed in Vervet monkeys, Campbell's monkeys have a "leopard!" call that can be combined with a suffix that changes its meaning to indicate a less specific threat:
Crucially, “krak” calls were exclusively given after detecting a leopard, suggesting that it functioned as a leopard alarm call, whereas the “krak-oo” was given to almost any disturbance, suggesting it functioned as a general alert call. Similarly, “hok” calls were almost exclusively associated with the presence of a crowned eagle (either a real eagle attack or in response to another monkey's eagle alarm calls), while “hok-oo” calls were given to a range of disturbances within the canopy, including the presence of an eagle or a neighbouring group (whose presence could sometimes be inferred by the vocal behaviour of the females).
Just as artificial intelligence researchers have been busy over the last several decades celebrating each previously-unique human capacity achieved by computers, biologists have been finding behaviors once thought to mark the uniqueness of humans in other animals. Neurobiologist and primatologist Robert Sapolski recently gave a lecture at Stanford about the uniqueness of humans, which provides a great overview of what we share and don't share with other animals (as is currently understood).
Similarly, primatologist Frans de Waal has made a career of describing the political, cultural, emotional and moral lives of primates. His work has illustrated the evolutionary breadth and depth of many human characteristics previously thought to be recent behavioral innovations without precedent and unique to our species.
As artificial intelligence research looks forward to recreating human capabilities it focuses our efforts to understand those capabilities. Similarly, in identifying in other animals capacities like syntax once thought to be unique to humans, we are afforded a clearer look back on the deep history and development of those capacities. Looked at this way, it actually did take millions of years to produce the works of Shakespeare.
Earlier this month, a small group of World War II Navajo Code Talkers – who are today in their eighties and nineties – marched as a group for the first time in the New York City Veteran's Day Parade as a way to raise awareness in the US about their wartime contribution. The Code Talkers were Navajo speakers recruited by the U.S Military for sending coded verbal messages by radio in World War II – an effort legendary today as producing “the only unbroken code in modern military history.”
This caught my attention partly because Navajo is a threatened language – while there are 150,000 speakers at last count and several thousand monolinguals, the word on the wire is that Navajo is losing ground to English among the youngest in the Navajo community – and children are, after all, the ones who decide a language’s fate.
I also had this question in the back of my mind – could a human language be used in such a way today? Granted, we have sophisticated computer encryption that pretty much renders any human generated code obsolete. But say for a moment that we didn’t, or couldn’t use digital technology… do we simply know too much about what is possible in human language? And failing that, is there any language out there esoteric and isolated enough that it could be put to such use?
First, to clarify, there is nothing inherent about the Navajo language that made the code uncrackable – a quick perusal of the recent press turns up descriptors like “ancient language” and “complex grammar” which could apply to any human language. The phrase “near isolate” also doesn’t make sense because Navajo is a language with many linguistic relatives in the Athabaskan group throughout the Southwestern US, Canada, and Alaska.
What made the code uncrackable at the time was a combination of factors – physical and social isolation of the Navajo speech community certainly did, as few non-Navajos spoke the language. Also, little was known linguistically about the language at the time, and linguistics outside of philology was itself a fledgling field of study. Most importantly, the code wasn’t just everyday Navajo, but a cipher based on Navajo with word-replacements like “tortoise” for tank or “iron fish” for submarine as well as Navajo substitutions for English military acronyms. A Navajo speaker was in fact captured and tortured for his knowledge at Bataan, but since he didn’t know the cipher, he was just as befuddled as everyone else.
I wonder though whether a linguist today with a basic knowledge of the language, and/or access to basic tools like a grammar and dictionary, transported back to that time might have figured it out, given enough data and the context in which the messages were delivered. A relatively few cracked messages could render the essential cryptographic key. Do all human languages have such basic description? Far from it. My best guess based on what we’ve been able to find for The Rosetta Project is maybe one half of all human languages? A third? Without this, the decryption task would have to encompass basic linguistic analysis as well.
So is it possible that a human language in this day and age could serve the purpose? Maybe, maybe not -- I welcome discussion. But if not – and here’s the real question on my mind – are we linguists done? Can we pack up our bags and go home? Although I think we understand something about human language – maybe a lot more than we did 70 years ago, it would be extreme hubris to say we really get all there is to human language at this point. I expect there are plenty of surprises in store even as far as grammatical structure is concerned – and at every level of structure. Many of the more interesting questions are likely to relate to how language is used in its cultural context -- like the Pirahã avoiding speaking about the remote past because it is inaccessible to eyewitness verification.
That many lifetimes could be spent puzzling it all out is one of the great joys of linguistic discovery. And to my way of thinking, the surprises about our human selves that lie in store is a primary reason to pursue language documentation as one of the great scientific and intellectual enterprises of our era.
Launched in 02004, Rosetta has made several planetary flybys in order to gain the velocity necessary to approach and eventually orbit the comet so that a small landing craft can touchdown upon and sample some of the comet's material. Scientists hope that a better understanding of the make-up of a comet will be like a key that will unlock many secrets about the formation of the planets and the development of our solar system.
Included on the craft is one of the early Rosetta Disks produced by Long Now. The highly durable, format-independent linguistic archive will survive as long as the craft continues to orbit Comet 67P. Unlike the Voyager Disks, this terrestrial artifact will remain in our solar system orbiting the comet, which is orbiting the Sun and will continue to do so until it runs into something (which could be quite a while).
You can see lots of greatphotos and amazing animations on the Rosetta blog, run by the ESA. In addition, there was a lovely little piece in the Guardian highlighting the mission's long-term nature:
Officially inaugurated in 02002, the Bibliotheca Alexandrina is an attempt by Egypt and the city of Alexandria to recreate, in spirit if not content, the original Library of Alexandria. The Ptolemaic dynasty of Egypt created what was at the time, the worlds largest library in the third century BC in the Egyptian city of Alexandria. Though historical accounts disagree as to how, why and when, this massive repository of centuries of scholastic work was burned down and lost to the ages.
Long Now Board Member Michael Keller sent in notice of his event coming up at Stanford University on December 2nd in which Dr. Ismail Serageldin will be discussing his work as the Director of the Bibliotheca Alexandrina and his hopes for better dialogue between the West and the Muslim world:
In a new announcement by the Australian government, the equivalent of $7.8 million US dollars will go towards programs that work to save endangered aboriginal languages.
Australia is one of the linguistically rich regions of the world, in recent history having upwards of 275 distinct languages. These languages also contain some fascinating linguistic features, such "mother-in-law" avoidance speech, unique noun class systems (witness the Dyirbal noun class for "women, fire, and dangerous things"), and words of surprising internal complexity (take for instance the Mayali word Abanyawoihwarrgahmarneganjginjeng. 'I cooked the wrong meat for them again'.)
Of these 275 languages, 111 are now extinct, and an additional 100 languages are considered to be critically endangered, with only a few elderly speakers remaining. To address this precipitous decline, the new program proposes to start with "translation services, tests for children and a feasibility study for a national centre for Aboriginal languages."
Programs like this may seem like too little too late, but declaring these languages "national treasures" can actually go a long way in creating a better climate for their continued use. A similar policy change came when the United States passed the Native American Languages Act of 1990, reversing decades of destructive government language policies, and setting up a grant program that continues to fund community-based language research to this day.
There is also support for aboriginal language documentation through a number of other grant programs, both large and small, that exist to support language documentation around the world. These include the Endangered Language Fund (ELF), the Foundation for Endangered Languages (FEL), the US Federal Documenting Endangered Languages program and a few private programs such as The Hans Rausing Endangered Languages Program and the Volkswagon Stiftung funded DoBes project. Each of these programs has been underway for several years, and combined, have a rich portfolio of successful projects to their credit.
(Thanks to Stewart Brand for passing this news item along.)
Here is an interesting example of a linguistic game, a crowdsourced translation, and a potential Rosetta Genesis Text to boot -- The Lolcat Bible (or, translated into Lolcat by yours truly: "teh Ceiling Cat goodmeow accordingz to teh kitteh"):
"At start, no has lyte. An Ceiling Cat sayz, i can haz lite? An lite wuz. An Ceiling Cat sawed teh lite, to seez stuffs, An splitted teh lite from dark but taht wuz ok cuz kittehs can see in teh dark An not tripz over nethin. An Ceiling Cat sayed light Day An dark no Day. It were FURST!!! "
You can read the rest here. And by the rest, I mean, all of it - the whole Bible translated into Lolcat - down to the book, chapter and verse. And, if you see something missing, you can add it yourself - it's a wiki.
A recent article in the New York Times describes the endangered language research of Tucker Childs, a linguist at Portland State University, who is in Sierra Leone studying the nearly extinct Kim language. The death of the Kim language is attributed to the decision of younger speakers to learn the Mende language, spoken by 1.5 million people in Sierra Leone and Liberia. This pattern of language loss is common, especially in the era of globalization, when the ability to communicate beyond a local village is essential for economic success.
The article suggests that Kim is beyond the point of revitalization, but this makes the effort to document the language even more urgent. By documenting the Kim language, and then depositing the documentation with the Hans Rausing Endangered Languages Project, Childs and his research team are working to make sure that knowledge of the Kim language will remain long after the language is no longer spoken. This kind of information can contribute a great deal to ongoing linguistic research (such as the study of linguistic typology and what is possible in human language) and in some cases, has even provided enough information to bring languages back into active use after generations have passed.
Technology for gathering language documentation has changed dramatically, just as language documentation efforts have redoubled in the face of rapid and massive language extinction. Audio and video recorders are all digital, and the work of building dictionaries and translating collected texts is now typically done on a laptop computer. One of the most moving parts of The Linguists, a documentary chronicling the work of two endangered language researchers (viewable for free on Babelgum), comes when the last speakers of Chulym, a language of Siberia, are able to immediately see a digital video recording of themselves speaking their native language, which was heavily supressed in the Soviet era.
While digital technology provides new tools in the effort to document the world's endangered languages, it also presents a challenge for archivists trying to preserve data that is "born digital" and only exists in a digital format. The Digital Endangered Languages and Musics Archive Network (DELAMAN), is a network of digital archives that support endangered language documentation by helping ensure that data remains safe, discoverable, accessible, and usable. Participating archives like The Rosetta Project are working to develop and promote robust archival practices around the long-term storage of linguistic data. Similar efforts have produced and promoted ISO 639-3 codes for 6,800 human languages, linguistics-specific metadata (see the Open Language Archives Community), and are promoting open and transparent file format standards for linguistic research (see the NSF-funded EMELD project)
Estimates of the number of the world's languages are hard to nail down precisely. Our best estimate comes from the current edition of the Ethnologue, which puts the number at 6,909... 6,909 languages. For a challenge, try naming a hundred. Fifty. Ten? The notion of living in a world with almost 7,000 languages is an abstraction for nearly everybody.
One way to potentially visualize this is by locating languages on the map. This may seem like a simple task, but the complexities become apparent when looking even at a single language such as English. Besides native speakers, there are many non-native speakers of English, who learn it as way to communicate with people around the world. How do you map these speakers? How do you show that English is spoken alongside many other languages, such as the many indigenous languages of North America and Australia? The complexity of language use calls for an approach to mapping that is more than placing a single point on a country, or even drawing geographic boundaries. A good map of the world's languages must account for the many ways in which we interact with language in our daily lives.
One attempt is LL-Map, shown here. This project, funded by the National Science Foundation, is working to integrate many different geo-linguistic factors into a single digital map interface. To date, this interface provides many different language map layers, combined with geographic data related to climate, political divisions, and flora and fauna, both historical and current. By integrating these layers, LL-Map provides a tool for those who hope to better understand and study the complex factors of language use worldwide.
Martin Schoeller's portraiture reveals an unexpected familiarity with his subjects, who range from the well-known to the anonymous. The photographer's portraits of Pirahã tribesmen serve as a compelling follow-up to the work of Daniel Everett, who recounted his experience living with the Amazonian community at one of our seminars in March. Schoeller's portraits appeared in the The New Yorkerand later in Everett's book, Don't Sleep, There are Snakes: Life and Language in the Amazonian Jungle.
The series, Pirahã Grid, is currently on display at Washington, D.C.'s, National Portrait Gallery, alongside other work featuring such familiar faces as President Barack Obama and Angelina Jolie. The subjects were shot close-up against a white background, in the kind of stark and intimate portrayal that academic studies rarely capture. Schoeller's photographic style exhibits a striking clarity of detail while decontextualizing the subjects in a manner that, according to the Gallery, questions "the very nature of the categories we use to compare and contrast."
From Schoeller's artist statement:
"In a close-up, the impact stems solely from the static subject’s expression or apparent lack thereof, so the viewer is challenged to read a face without the benefit of the environmental cues we naturally use to form our interpersonal reactions."
The series will be on display in the Gallery until September 29th of this year.
Over at The Rosetta Project, we have been busy uploading new materials to our collection at the Internet Archive (which you can also follow by RSS feed). This week, we uploaded this grammar of Esperanto -- a language invented by a single man, now used as a means of regular communication by thousands, if not millions of speakers!
The language is the brainchild of Ludwik Zamenhof, an ophthalmologist from the city of Biyalstok (then part of the Russian Empire, now in eastern Poland). In the late 19th century, the city was divided between Germans, Jews, Russians, and Poles, who all spoke their own language. The animosity between these ethnic groups convinced Zamenhof that the key to understanding and harmony would be a common language.
The structure of Esperanto (the name means, in Esperanto, "one who hopes") reflects this ideal. The vocabulary, grammar, and sound system incorporate elements from all major European languages, and the structure is completely regular, making Esperanto very easy to learn. While the original goal of being a universally adopted language is still a bit far off, the Ethnologue estimates that there are 2 million speakers worldwide, with as many as 2,000 who learned Esperanto as their native language.
That's right, native Esperanto speakers. Couples who have met at Esperanto conventions will have no common language other than Esperanto, meaning that their children often grow up in an Esperanto-speaking household. The list of native Esperanto speakers includes a Nobel Prize laureate.
Well and good. But why should you learn Esperanto? A whole wealth of culture would be at your fingertips, with over 25,000 books available (original and translated), and a 1965 horror movie starring William Shatner (a familiar presence to speakers of another artificial language, Klingon). Pasporta Servo is an international organization of Esperanto speakers in 92 countries who will give fellow Esperantists a place to stay. Akademio Internacia de Sciencoj (International Academy of Sciences) is an Esperanto-language university. Research has shown that learning Esperanto is a good stepping-stone into learning other languages. A pilot program in the UK teaches Esperanto to schoolchildren before they take on more complex and irregular human languages.
The author of a "Complete Grammar of Esperanto," Ivy Kellerman Reed, was an influential American Esperantist at the beginning of the 20th century, a time when ekscito was in the air, and the Esperanto revolution was heating up. Her preface to the book states "[This book] is to furnish not merely an introduction to Esperanto, or a superficial acquaintance with it, but a genuine understanding of the language and mastery of its use without recourse to additional textbooks, readers, etc." All this can be gained in a tidy 345 pages, counting a small Esperanto-English dictionary in the back. The book also reads well using the FlipBook, a slick innovation by the Internet Archive.
To any future Esperantists we may have inspired, we can only say Bonan ?ancon!
With the passing of Cahuilla elder Alvino Siva on June 26, the language of the Cahuilla of Southern California moved one step closer to being lost forever. Silva was one of just a handful of fluent Cahuilla speakers left. A 1994 estimate placed the total number of speakers between 7 and 20, all elderly. Cahuilla is one of the 516 languages listed by the Ethnologue as critically endangered, and linguists estimate that we may lose as much as 90% of the world's 6,800 languages in the next century -- an average of one human language per week.
Siva was especially interested in teaching and preserving Cahuilla bird songs, which tell the origins and history of the Cahuilla people. The debut of the documentary "Sing Birds: Following the Path of Cahuilla Power," at Idyllwild Arts Academy, chronicles this rich oral history. Siva's interviews, along with those of two other Cahuilla elders, feature prominently in the film.
The Rosetta Project Archive houses more than 30 Cahuilla recordings, assembled in the fall of 1937 by John P. Harrington, some of which include performances of bird songs (available in this Google Earth Layer). During 40 years as a field ethnologist for the Smithsonian, Harrington collected recordings of languages throughout California and the Americas, including Cahuilla. The original wax cylinder and aluminum disk recordings are now kept at the National Anthropological Archives in the Smithsonian. The Rosetta Project Archive also includes a Cahuilla grammar and set of texts that you can find in our special collection in the Internet Archive.
This recent study has found that monkeys are able to discern the prefixes and suffixes of human language. These word parts are essential to the grammars of many languages -- including English, where verbs are changed by the addition of suffixes to mark things like tense, aspect, person and number (hear-d, hear-s, hear-ing, etc.).
In the study, Cottontop Tamarin monkeys (pictured on the left) were made to listen to human speakers modifying a fictitious word base "shoy". The monkeys would grow accustomed to hearing a phrase such as "shoy-bi," where "bi" functions as a suffix. When the monkeys heard "bi-shoy" -- turning "bi" into a prefix -- they reacted by turning to the researcher playing the recording, indicating they were aware of the inconsistency in the sound pattern. What's more, the monkeys were able to recognize the change after hearing a single phrase only a few times.
Lead Author Ansgar Endress, a researcher at Harvard University, sees a parallel in the way human babies learn the rules of affixation in a language by tracking the position of speech sounds in relation to one another. By identifying this cognitive function in other animals, he suggests that the ability to comprehend and categorize affixation, a key mechanism driving human language, may have evolved for a non-linguistic purpose.
(By the way, we here at The Rosetta Project aren't really worried about having our jobs outsourced to other primates, since they haven't been shown to be able to parse infixes, circumfixes, much less nonconcatenative morphology. And they can't type very well. Now, being replaced by machines... this has us a little worried!)
The Codex Sinaiticus, the oldest extant copy of the Bible, has been digitized by the Codex Sinaiticus Project, and can now be viewed online here. The manuscript contains the entire New Testament, and most of the Old Testament, all in Greek (the original language of the New Testament). The physical manuscript is divided unequally among four locations in Britain, Germany, Russia, and Egypt, so the online version marks the first time the Codex can be viewed in its entirety in 100 years, when the first part was taken from St. Catherine's Monastery on Mount Sinai.
The Rosetta Project Language Archive includes a Greek Septuagint translation of the first three chapters of Genesis. This landmark Greek translation holds great historical significance, since it was the preferred translation of most Early Christian writers, including Paul, and is the text quoted throughout the New Testament.
Stewart forwards this beautifully detailed rendering of the Rosetta Mission by artist Erik Viktor, showing the landing craft on the icy surface of Comet 67P/Churyumov-Gerasiamenko and the sun beyond. The main spacecraft above is the orbiter, with 14 meter solar panels on each side. The orbiter has eleven groups of scientific instruments, intended to take readings from the lander, and relay them back to earth. The prototype Rosetta Disk is also on the orbiter, located on the exterior underneath thermal blankets. The orbiter is due to rendezvous with the comet in 02014.
"Japanese researchers prototyped a memory system that can store large volumes of data for more than a thousand years. The system, "Digital Rosetta Stone (DRS)," was announced June 16, 2009, by Keio University, Sharp Corp and Kyoto University at the 2009 Symposium on VLSI Circuits, which is taking place in Kyoto, Japan (lecture number: C3-3). They stacked wafers mounted with mask ROM and packaged it with SiO2. Power supply and signal communication are conducted by wireless."
Very, very cool... but there remains the issue of transparency. If someone finds this disk 1,000 years from now, how will they know how to access the information? We think a microetched instruction manual might do very nicely.
Whether the language you speak fundamentally shapes your thinking (sometimes referred to as "linguistic relativity") is a question that usually comes up in Linguistics 101, along with a set of well known examples -- Hopi time, Eskimo words for snow -- that would seem, a priori, to indicate the answer is "yes". Recent research, however, conducted by Lera Boroditsky and discussed in her contribution to "What's Next? Dispatches on the Future of Science" go a long way towards actually proving this is the case.
"We gave people sets of pictures that showed some kind of temporal progression (e.g., pictures of a man aging, or a crocodile growing, or a banana being eaten). Their job was to arrange the shuffled photos on the ground to show the correct temporal order. We tested each person in two separate sittings, each time facing in a different cardinal direction. If you ask English speakers to do this, they'll arrange the cards so that time proceeds from left to right. Hebrew speakers will tend to lay out the cards from right to left, showing that writing direction in a language plays a role. So what about folks like the Kuuk Thaayorre, who don't use words like "left" and "right"? What will they do?
The Kuuk Thaayorre did not arrange the cards more often from left to right than from right to left, nor more toward or away from the body. But their arrangements were not random: there was a pattern, just a different one from that of English speakers. Instead of arranging time from left to right, they arranged it from east to west. That is, when they were seated facing south, the cards went left to right. When they faced north, the cards went from right to left. When they faced east, the cards came toward the body and so on. This was true even though we never told any of our subjects which direction they faced. The Kuuk Thaayorre not only knew that already (usually much better than I did), but they also spontaneously used this spatial orientation to construct their representations of time."
I have just stumbled across the Cuneiform Digital Library Initiative (CDLI), which contains images and catalog information for cuneiform tablets dating from ca. 3350 B.C., or the age when writing began. As of February 8, 2008, the collection contained 225,000 cuneiform texts and 85,000 images. The CDLI brings together the collections of sixteen digital library collections.
The collection is gorgeously photographed and allows you to zoom in to a degree on each of the tablets. Not only is it a joy to peruse, but it is exhillarating to see so many ancient texts from over 5,000 years ago.
The image shown is from The Hearst Museum of Anthropology at UC Berkeley and is from the Early Dynastic period, or ca. 2600-2350 B.C.
What do Klingon, Elvish and Esperanto have in common? They are all explicitly constructed languages -- some for fictional worlds, some for the real world. Some are created to entertain, others have such lofty goals as achieving world peace. Some have dictionaries, grammars and language academies. All have a fair number of real world speakers, and probably even a few native speakers. But none, so far, have been the subject of serious linguistic inquiry...until now.
We at The Rosetta Project have always thought invented languages are totally cool (after all, philologist J.R.R. Tolkien wrote in his letters that he created Middle Earth as a way to showcase his invented languages and what could be cooler than that?). The invented languages Esperanto and Interlingua are both represented the Rosetta Disk -- we have Genesis translations for both (hint: look in the European region for languages of France).
While the FOXP2 gene is important in the development of many different tissues, in humans it affects the development of the basal ganglia, a region of the brain important for language. When the human version of FOXP2 is introduced into mice, a measurable result is a change in their ultrasonic vocalizations - baby mice have deeper squeaks. While this is interesting, and the kind of correlation one might expect, even more striking is what is going on in the brains of these mice -- the mean length of dendrites in the basal ganglia region increased by 80% over mice without the human version of the gene.
This groundbreaking study, with results recently published in the journal Cell, provides a new a model for research into how speech and language evolved in humans.
Put down your crosswords, cryptograms and sudoku. Instead try boosting your brain power by deciphering an ancient script. In case you have forgotten which ones are still available and want to stake your claim, here is a catalog with difficulty ranking based on two important criteria: language (known/unknown) and script (known/unknown). All have teased many a brain for many an age.
Other things you might want to consider when selecting your brain challenge: is the script artifact a hoax (see Phaistos Disk)? Does it even represent spoken language (see recent work and controversy over the Indus Valley Script)? Also, beware of the possibility of unleashing an army of undead if you actually do figure out the script and recite it (for a vision of this scenario, see Evil Dead II).
The good folks over at the Jet Propulsion Labs in Pasadena who organized the Data and Art show that the Rosetta Disk was in, were kind enough to get some really nice photos taken of the micro-etched data side of the disk. What you are looking at is over 13,000 tiny pages describing over 1,500 languages. To see each page you would need a 500x microscope.
Many thanks to Dan Goods at JPL and especially Spencer Mishlen for this gorgeous work. I really love how the page rows start to look like the Matrix as you zoom in...
Can a logographic script of a major world language survive its own government bureaucracy? As reported in the NY Times:
"Seeking to modernize its vast database on China’s 1.3 billion citizens, the government’s Public Security Bureau has been replacing the handwritten identity card that every Chinese must carry with a computer-readable one, complete with color photos and embedded microchips. The bureau’s computers, however, are programmed to read only 32,252 of the roughly 55,000 Chinese characters, according to a 2006 government report. The result is that at least some of the 60 million other Chinese with obscure characters in their names cannot get new cards — unless they change their names to something more common."
Wired magazine has a very good piece this month on what many are calling the American Stonehenge, (though it's not the only site to receive this moniker). 90 miles east of Atlanta lies a mysterious and controversial monument known as the Georgia Guidestones.
In a field north of a small town called Elberton, four 16-foot tall granite slabs stand aligned to the cardinal directions. They are centered around a central pillar with a fifth piece of granite resting on top. The full monument is almost 20 feet tall and weighs over 100 tons. Constructing the monument was no easy feat, even for the experienced granite workers of Elbert County, which calls itself "The Granite Capital of the World."
In the central column, a hole is drilled that aligns with the North Star (for now, anway). It also contains a slot that allows viewers to see the Sun's position as it sets on the equinoxes and solstices. An opening in the capstone create a beam of sunlight that shines onto the central pillar at noon and indicates the day of the year.
The Guidestones were erected in 1980 with the direction of a man operating (and funding the pricey project) under the pseudonym R. C. Christian. While their purpose isn't exactly clear, a tablet set into the ground nearby proclaims,
Let these be guidestones to an Age of Reason.
The Guidestones are covered in inscriptions written in 8 major languages that describe the tenets of their imagined Age of Reason. They seem to be a prescription for a utopia, albeit, one with limited access - the first tenet reads,
MAINTAIN HUMANITY UNDER 500,000,000 IN PERPETUAL BALANCE WITH NATURE
These tenets (some are calling them commandments) line up pretty closely with what many conspiracy theorists, especially those with a religious bent, imagine to be the plot of either the Antichrist or the New World Order. Searching online about the Guidestones turns up more conspiracy theory pages than fansites:
The Guidestones were vandalized last winter and, though nobody has yet marshaled the resources to actually do it, calls for their destruction are not uncommon. Thus far, Elbert County appreciates the controversy's effect as a tourist draw and probably appreciates the way it highlights their granite industry.
As for the Guidestones' likelihood to survive, it is interesting to note that the surrounding mystery has been both a help and a hindrance. By instilling wonder and encouraging curiosity, the secretive creators have generated a good deal of interest in the monument. They've also, however, allowed some blanks to be filled by people offended by the little that is discernible about their agenda.
In an article published in the April 24 issue of Sciences, researchers describe how they applied a computational process called "comparative entropy" to a corpus of ancient Indus Valley Script texts. The results of the analysis show a kind of patterning they argue is only found in glottographic, or speech-based, writing systems. The complex Indus Valley civilization flourished from 2,600 to 1,900 B.C. and left hundreds of engravings on seals and tablets -- writings which have yet to be deciphered.
Members of the AAAS can read the Science article online here. Otherwise this Asia Times Online article has a summary that describes historical attempts at identifying the script that would rival the storied Rosetta Stone.
Oromo, a language of Ethiopia with about 9,000,000 speakers, now joins languages like Mandarin, English and Spanish -- languages with hundreds of millions of speakers -- (and yes, Elmer Fudd-speak and Klingon) as the newest addition to Google's multilingual interface. This translation effort was made possible by over four years of work by dedicated volunteers using the "Google in Your Language" program.
According to Qeerransoo Biyyaa, one of the Afaan Oromoo translation team members, the translation effort "was a huge struggle as a person needs to integrate concepts from technology, language and culture simultaneously. It was sometimes hard to find equivalent technological terms in Oromo or other language from Ethiopia. This is simply because technological terms are as foreign as the technologies themselves to Ethiopia."
A fully browseable version of the Rosetta Disk is now available online at The Rosetta Project website. Using this link, you can virtually browse and explore the contents of the disk, just as you would if you were looking at the micro-etched Rosetta Disk with a high-powered microscope. The viewer for the digital version of the Rosetta Disk on this DVD was built by Kurt Bollacker, using the OpenLayers 2.5 map visualization framework.
The browseable Rosetta Disk is temporarily replacing the content of the previous Rosetta Archive site, while we build out a new architecture for Rosetta that will make it much easier to access, use and repurpose Rosetta Data. Our new site is still under wraps, but we are very pleased to say that its distributed architecture involves both the Internet Archive -- a caretaker for one of the original Rosetta Disks -- and the open database site Freebase. Meanwhile all Rosetta data is safe, sound, and continues to be backed up by Stanford University Libraries.
Stay tuned for more on this channel, and meanwhile, happy disk browsing!
Two recent TED talks present a striking contrast in what the near-term future of human communication might be like -- a multilingual world increasingly enabled by technology, or one where we all learn a lingua franca to participate in global public discourse.
Given that one out of every six people on the planet speak Mandarin as a native language, the latter possibility is easy to imagine. And, when you take second language speakers into account, English is certainly a contender for that number one spot, as Jay Walker's recent TED University talk makes abundantly clear:
But what about when technology enters the mix? Taken in aggregate, the "long-tail" of languages (that is, everybody else) is a pretty big group. As websites and mobile communication devices increasingly enable electronic communication in the world's languages, and people realize the advantages of communicating with people in the roughly 6,500 languages of "home and heart"... well, maybe the long tail is itself a contender.
Here's a glimpse of what that future might be like:
The Wall St Journal ran a piece in their January 2nd Edition on the narrow group of languages that can use SMS cell phone text messaging. Our very own Laura Welcher was quoted in the article:
"The idea of having your cultural identity represented in this technology is increasingly important," says Laura Welcher, director of the Rosetta Project of San Francisco's Long Now Foundation. Ms. Welcher, who says linguists fear half the world's languages will disappear in the near future, thinks at least 200 languages have enough speakers to justify development of cellphone text systems. "Technology empowers the poorest people," she adds.
A fully browseable version of the Rosetta Disk is now available on DVD from The Long Now store ($15).
The viewer on the DVD is powered by the OpenLayers 2.5 map visualization framework, which allows you to zoom all the way in to read even the microscopic text on both the front and back of the disk. The front side (shown here) is an index listing the 1,500 languages on the disk, and the back contains over 13,000 pages of text with documentation on those languages. Together, both sides of the disk store a collection of information that attests to a richness of our human cultural and linguistic diversity in the 21st century.
One of the principles of archiving is to make and distribute multiple copies of information. This principle goes by the moniker LOCKSS 'Lots of Copies Keeps Stuff Safe' -- if some copies go missing, others will hopefully survive. And the more copies out there, the better the chance of some surviving. Now, by owning a copy of The Rosetta Disk DVD, you can take part in helping preserve this information for the future.
An archive of the world's languages makes a great holiday gift! Proceeds from the sale of the DVD go to support continued work on The Rosetta Project.
If Indiana Jones had been created by Gabriel Garcia Marquez and Stephen Pinker instead of Lucas and Spielberg, he might have been something like Daniel Everett. His story is as visceral as it is intellectual - it's got love, beauty, pain and suffering in the South American jungle and a high-stakes search to understand the cognitive underpinnings of human language.
Everett has simultaneously produced a ground-breaking linguistic anthropology text and a riveting, powerful memoir about life lessons learned on missionary work in the Amazon. Don't Sleep, There are Snakes: Life and Language in the Amazonian Jungle was released on November 11th and he'll be presenting "Endangered Languages, Lost Knowledge and the Future" as one of our Seminars About Long-term Thinking on March 20th, 02009.
Daniel Everett lived for 7 years throughout 3 decades among an isolated Amazonian tribe called the Pirahã, initially in order to convert them to Christianity. These unique people speak a language that defies long-standing theories and live a simple, hard life as hunter-gatherers. His time among them caused Everett to renounce both Christian faith and some of the basic tenets of modern linguistic theory.
Don't Sleep, There are Snakes includes Everett's descriptions of the overwhelming beauty of the jungle (something he couldn't help but notice even while desperately canoeing his entire family up an unfamiliar stretch of river to save his wife and daughter from malaria), harrowing life-or-death struggles (see above), and thoughts on the implications of a people that speak without embedded clauses or a perfect tense (things, demonstrated by this sentence, I obviously can't live without).
The book has been reviewed by Time and the London Times. A New Yorker article about Everett's work has been discussed here previously. And if you're wondering about the title, it comes from the Pirahã's lack of small-talk such as 'Hello' or 'How are you?': Instead of wishing someone 'Goodnight,' they offer a pragmatic reminder of the omnipresent dangers of jungle life.
Buy the book from Amazon through Long Now's Store page and Long Now gets 15%.
Through our partnership with Applied Minds we were invited to include one of our materials on a NASA material experiment called MISSE on the International Space Station. We included a sample of commercially pure titanium, that was black oxide coated, and laser etched (pictured below). This is the same material/process that we made the front side of the Rosetta Disk out of. Now we get to find out how well the disk would hold up if exposed to open space for several years...
This experiment is a continuation of sorts of the material research started back in 01984 with the Long Duration Exposure Facility that Kevin Kelly posted about earlier.
In a remote region of India, students at the Adivasi Academy are working to save their tribal languages, and through their languages, their tribal cultures and knowledge as well. They certainly have their work cut out for them -- many of the students have had to devise writing systems for their historically unwritten native tongues only to embark on the herculean task of developing dictionaries, grammars and other major reference works (consider that Noah Webster's dictionary was the product of decades of work -- and a dictionary is but one part of these students' undertaking.)
The term adivasi refers to the indigenous people of India, who belong to remote tribal groups and speak many different dialects. These languages are rapidly being engulfed by urban languages with greater economic utility and prestige. One student, Kantilal Mahala, a speaker of the Kunkna [Konkani] language remarked, “In my village, people who move ahead speak only Gujarati. They feel ashamed of our language." But documentation projects like these can help change perceptions, raising the prestige of the language and its speakers through a new written standard and medium for wider communication -- this, and the fact of the Academy's very existence, which affirms 'we are here, and we are worth this effort.'
We now have both the sides of the disk micro-etched. The front human eye readable side (pictured above) was a challenge as it had etching that went from very large to the very small. The eight outer spiraling texts start with characters about a centimeter high and end up with characters a few hundred microns high. And the language names surrounding the earth image were small enough we had to get a special engravers style font made in Germany to make sure they would stay legible. This side of the disk was etched into commercially pure titanium that was coated with a black oxide coating. This coating was then etched through with an eximer laser by a micro-etching company Norsam Technologies. One of their challenges was etching the center of the letters as well as the outlines. They had to create a crosshatching pattern for the 10 micron wide eximer beam to pass back and forth over the fill areas. Each one takes over 36 hours to etch.
Each of these are mated up with the other micro etched side of the disk with over 13,000 pages of language translations in a stainless bezel. (see below)
Each of the five first edition disks are going to still two of these remaining for any donor Rosetta Project donors of at least $25,000 (Contact Laura if interested in future editions). They each come in a protective stainless and glass spherical protective case. We are now working on more economical versions that we can more widely distribute. We have already produced a DVD version with all the content and a Java based viewer to view it in a kind of "virtual magnifying" glass format.
When you open the case and lift out the disk, there is a space underneath which holds a strip of stainless and a stylus to allow each generation who owns that Rosetta disk to mark down their ownership (pictured at the top of this post).
It took us eight years to get to this point. Whew.
Surreptitious crowd sourced book digitizing... one word at a time.
Last night I attended the Internet Archive's Open Content Alliance meeting. I was really amazed by how far their book scanning, (over a million books now), and contextualizing projects have come. The two most amazing things were the blog embed tools for the scanned book interface (more on that soon), and the most amazing use of Captcha technology I have seen. One of the inventors of Captcha's, those funny squiggly words used to prove your a human when you sign up for something, has now put this wasted time and human brain power to work.
ReCaptcha is now getting its difficult to decipher words from scanning projects like the Internet Archive's and is using the human effort to digitize the words the computer cant recognize. Over a half million man hours a year can now go to digitizing books instead of just wasting your time.
During his presentation at Pop!Tech 2008: Scarcity and Abundance, Dr. K. David Harrison discussed how language death leads to intellectual impoverishment in all fields of science and culture. He also detailed efforts to sustain, value and revitalize linguistic diversity worldwide. His talk was presented in collaboration with the multilingual video captioning site DotSub, where it is posted and now translated into 31 languages:
Closing his presentation, Dr. Harrison says;
“everyone can do something to support a world in which a diversity of thought and a diversity of ways of speaking is encouraged and is fostered and is sustained. There’s no reason for people to be forced to abandon their languages. It’s one of the false choices of globalization to tell people that they must give up a small or minority or a heritage language in order to speak a global language like English. It doesn’t have to happen. We would all be better and smarter if the world remains multilingual."
If you would like to help keep the world multilingual, you can translate this video yourself. Log in to DotSub, go to the video page, and select your language from the pull down list under "Translate and Transcribe."
We are testing out a crowd-sourced method of translation and subtitling of our Seminar series called DotSub.com. The first of twelve talks we are going to try this with is the Will Wright Brian Eno talk (as seen above). We have added the full English time coded transcript, and welcome any help in translating it into other languages. Dot Sub has a great interface that allows you to easily type in text that instantly becomes the sub-titles.
So please do try it out, and give us feedback here as comments to this post. Once we get several of these we will look at ways to localize a set of Seminar pages into various languages that we have translations for. Thank you.
Last week the Rosetta craft (carrying our prototype Rosetta Disk) successfully recorded its flyby of Steins Asteroid with these -- the first images from its OSIRIS imaging system (also check out this cool animation). During the flyby, the craft was out of communication for approximately 90 minutes - what must have been a nerve-wracking, although planned silence, as the teams engineers turned Rosetta away from the sun.
The Steins Asteroid was the first scientific target for the Rosetta craft as it makes its way to the comet 67/P Churyumov-Gerasimenko. From the collected data, the team's scientists hope to better understand the composition and formation of the unusually bright asteroid .
Paper, it turns out, is a very reliable backup medium for information. While it can burn or dissolve in water, good acid-free versions of paper are otherwise stable over the long term, cheap to warehouse, and oblivious to technological change because its pages are "eye-scanable." No special devices needed. Well-made, well-cared for paper can last 1,000 years easily, and probably reach 2,000 without much extra trouble.
Yesterday at the Long Now Museum, board members, staff and guests raised a glass to celebrate the completion of the first version of the complete Rosetta Disk. Over eight years in development, the Disk is a physical, microscopic library of information on over 1,500 human languages. 14,000 text and image pages are etched into the surface of a 3'' diameter nickel disk, which can be read with approximately 750x (optical) magnification.
The nickel disk has a high resistance to corrosion, and can withstand temperatures of up to 300 oC with little to no change in legibility of the text. Kept in its protective sphere to avoid scratches, it could easily last and be read 2,000 years into the future!
Joining in the celebration was Oliver Wilke, proud owner of a new Rosetta Disk (shown reflected in the Rosetta sphere on the left, above). The disk will be a centerpiece for his new foundation in support of endangered and minority languages around the world.
So... if the Rosetta Disk is a prototype and facet of the Library of Ages (companion to the 10,000 Year Clock), what goes into the fine print next?
Since its launch in 2005, Google Earth has become a valuable tool for sharing information of global scale. Its accessible platform and wide distribution has led to a wealth of independently created “layers” exploring a huge variety of topics.
The Rosetta archive is by design an explicitly global collection, and by nature relevant to every human occupied corner of the world. With its own global focus, Google Earth makes an ideal showcase for our data. To explore this we’ve created pilot layers that bring out some of the cool ways we see our language data interacting with the Google Earth interface. At the moment the layers bring just snippets of our archive to the surface, and we’re excited to bring the full depth of our materials to bear in future collections.
The files highlight some of the most intriguing aspects of the Rosetta database. You can browse endangered languages of Africa and the Americas, listen to recordings, and explore our 3D representation of linguistic diversity in the urban centers of the U.S. west coast. Check the files out here.
As this is a pilot project, we look forward to hearing your comments and suggestions, and we'd love to hear ideas for future implementations.
During its recent gravity assist flyby, the Rosetta craft was mistaken for an Earth-threatening asteroid! From Sky and Telescope:
"The spacecraft was unknowingly 'discovered' on November 7th by astronomers in Arizona scanning the skies for Earth-threatening asteroids. They dutifully reported the 20th-magnitude blip in their images to the Minor Planet Center here in Cambridge, and the next day the MPC announced that the newfound object, now designated 2007 VN84, would have a close brush with Earth...
An observant Russian skygazer named Denis Denisenko was the first to point out that 2007 VN84 was, in fact, Rosetta. The connection had been missed apparently because no one from the European Space Agency had bothered to update the MPC as to Rosetta's recent whereabouts. And so on November 9th the Cambridge clearinghouse issued an Editorial Notice to declare that 'The minor planet 2007 VN84 does not exist and the designation is to be retired.'"
Well, maybe we'll keep the designation around... to refer to Rosetta's 15 minutes of minor planetary fame!
"Europe's Rosetta spacecraft is rapidly approaching Earth for a close flyby on Nov. 13th. The gravity assist maneuver, bringing the probe only 5301 km above the Pacific Ocean, will fling Rosetta toward its 10-year destination: Comet 67/P Churyumov-Gerasimenko. Amateur astronomers with mid-sized backyard telescopes and CCD cameras can observe the approach; Rosetta is a 18th magnitude speck of light in the constellation Lynx: ephemeris."
This week, tech sites like DomainInformer reported that ICANN (the Internet Corporation for Assigned Names and Numbers) was unveiling the internationalization of top-level domain names in "11 test languages -- Arabic, Persian, Chinese (simplified and traditional), Russian, Hindi, Greek, Korean, Yiddish, Japanese, and Tamil." Uh…wait a second…did they say Yiddish?!! A language with around 3 million speakers in the company of languages like Hindi, which has an estimated 500 million speakers, and Mandarin, with about 1 billion? Well, all we can say here at Rosetta is…how cool! It’s not every day that a minority language gets as much attention as the big shots.
Before getting too excited though, we should probably note that what’s actually being counting here is scripts…writing systems…rather than languages per se. This is why Chinese makes the list twice: for the simplified as well as traditional writing system. If we were counting languages, “Chinese” would include a lot more – since linguistically speaking, Mandarin is one of many Chinese languages.
The reason for listing Yiddish, a language closely related to German, rather than the more obvious Hebrew, a Semitic language and national language of the State of Israel, is that although both use roughly the same script, Yiddish requires the use of few additional diacritics. What works for Yiddish, should therefore work for Hebrew as well, although ICANN is certainly open to discussion of this topic on the IDNwiki.
This internationalization effort is certainly good news for speakers and typers of Yiddish worldwide, as well as the hundreds of millions of people who regularly use non-Roman scripts online, and who will now be able to have top-level domain names (.com, .gov, etc.) written in the same script as the rest of the domain.
The New York Times reported yesterday on the crisis of language loss, and the work of linguists to document languages that are on the brink of vanishing without a trace. This picture of linguists David Harrison and Greg Anderson, and Charlie Muldunga, the only known speaker of Amurdag (a language of the Northern Territory previously thought to be extinct), shows that the tools of this enterprise are quite simple and inexpensive: an audio or video recorder and good ol' paper and pencil. With the right training, even short periods of work between linguists and speakers can yield a wealth of valuable documentation.
In the past, linguistic documentation like the kind being made here was distilled into scientific publications that illustrated unique features of a language, or that supported or disproved particular theories of grammatical structure. Now, with heightened awareness of the impending loss of global linguistic diversity, language minority researchers and advocates are realizing the tremendous value of this documentation itself. It can be used by many people, for many different purposes – by scientists interested in the grammatical or typological properties of language, to communities whose heritage culture is represented and embodied by these languages. With enough interest, motivation and effort, this documentation can even provide the seeds of language revitalization, where communities reinvigorate a language and bring it back into active use.
But there is another concern: these incredible resources can become endangered themselves – mouldering on dusty shelves, forgotten in people's attics or garages, until daughters or grandsons find them and not knowing their value, sweep them into the dustbin. Even digital documentation is at risk, if not from lapsing into similar obscurity, then sinking into a digital format obsolescence that renders them practically unrecoverable. A growing number of archives and digital efforts like The Rosetta Project are working to prevent this from happening, by providing format conversion, safe storage, and most importantly public access. In the end, it is people knowing and caring about these languages that will help bring them back from the brink.
Note: It turns out we can't link to the Amurdag language in The Rosetta Project, since its not on the books, so to speak. It was previously thought to be extinct until this single speaker Charlie Muldunga was found. Yeah -- oops! But this turns out to be a known phenomena in Australia, and has to do with ideas of multilingualism, language identity, and who can claim to be a speaker of a language.
This is a great appendix I just came across on the half life of vocabulary in a language. From the text:
The rate of vocabulary change The half-life of a word is the amount of time required for there to be a 50% chance that it will be replaced by a new word. Most words have a half-life of 2,000 years. However, a small number of words have a half-life of greater than 10,000 years. This shows that despite the fast average pace of language evolution, some meanings, like highly-conserved genes, evolve at a slow rate. The y axis in the graphic is the number out of a sample of 200 meanings. (ref. 1)
San Bushman in Namibia. Linguists say the 'click' sound used in San speech may have been a feature of the proto-language.
Linguists seek a time when we spoke as one
A controversial research project is trying to trace all human language to a common root.
Nice article (CS Monitor) forwarded to me by Paul Saffo on the search for a single proto-language from which all others came. In the last seven years of the Rosetta Project our data has been used by linguists to try and prove out this theory including the work at Sante Fe Institute mentioned in the article.
I recently came across this very nice animation of the last 2907 years of alphabet evolution. It is a remarkably condensing and simple animated illustration.
The story is about trying to crack the language of the Pirahã, a tribe in South America, whos language and culture arguably defies almost all linguistic and behavioral convention. The story twists and turns through academia, Chomsky, the Amazon, missionary groups, bible translators, and the 25 year relationship of one field linguist with this exceptional tribe.
On January 2nd of 02007 Stewart Brand and I stepped into the cool deep past and unknown future of who begat who.
The Granite Genealogical Vaults
Since I began working on the 10,000 Year Clock project, and associated Library projects here at Long Now almost a decade ago, I have heard cryptic references to this archive. We have visited the nuclear waste repositories, historical sites, and many other long term structures to look for inspiration. However we had never found a way to see this facility. This is the underground bunker where the Mormons keep their genealogical backup data, deep in the solid granite cliffs of Little Cottonwood Canyon, outside Salt Lake City. UT.
The Church has been collecting genealogical data from all the sources it can get its hands on, from all over the world, for over 100 years. They have become the largest such repository, and the data itself is open to anyone who uses their website, or comes to their buildings in downtown Salt Lake City.
However they dont do public tours of the Granite Vaults where all the original microfilm is kept for security and preservation reasons. Since Stewart had recently given a talk at Brigam Young University we were able to request access, and the Church graciously took us out to lunch and gave us a tour.
 Speaker using the Aikuma app
Speaker using the Aikuma app



 Some Unicode Symbols for Egyptian Hieroglyphs
Some Unicode Symbols for Egyptian Hieroglyphs




















 "
"













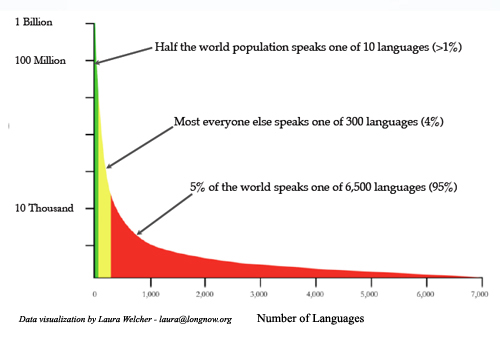











 In a new announcement by the Australian government, the equivalent of $7.8 million US dollars will go towards programs that work to save endangered aboriginal languages.
In a new announcement by the Australian government, the equivalent of $7.8 million US dollars will go towards programs that work to save endangered aboriginal languages.
 A
A 

 Over at The Rosetta Project, we have been busy uploading new materials to our
Over at The Rosetta Project, we have been busy uploading new materials to our  With the passing of Cahuilla elder
With the passing of Cahuilla elder  This
This  The Codex Sinaiticus, the oldest extant copy of the Bible, has been digitized by the Codex Sinaiticus Project, and can now be viewed online
The Codex Sinaiticus, the oldest extant copy of the Bible, has been digitized by the Codex Sinaiticus Project, and can now be viewed online 

 Whether the language you speak fundamentally shapes your thinking (sometimes referred to as "linguistic relativity") is a question that usually comes up in Linguistics 101, along with a set of well known examples -- Hopi time, Eskimo words for snow -- that would seem, a priori, to indicate the answer is "yes". Recent research, however, conducted by Lera Boroditsky and discussed in her contribution to "
Whether the language you speak fundamentally shapes your thinking (sometimes referred to as "linguistic relativity") is a question that usually comes up in Linguistics 101, along with a set of well known examples -- Hopi time, Eskimo words for snow -- that would seem, a priori, to indicate the answer is "yes". Recent research, however, conducted by Lera Boroditsky and discussed in her contribution to " I have just stumbled across the
I have just stumbled across the 
 What happens when you substitute the human FOXP2 gene for that of a mouse? According to
What happens when you substitute the human FOXP2 gene for that of a mouse? According to 
 Put down your crosswords, cryptograms and sudoku. Instead try boosting your brain power by deciphering an ancient script. In case you have forgotten which ones are still available and want to stake your claim,
Put down your crosswords, cryptograms and sudoku. Instead try boosting your brain power by deciphering an ancient script. In case you have forgotten which ones are still available and want to stake your claim, 


 In an article published in the April 24 issue of Sciences, researchers describe how they applied a computational process called "comparative entropy" to a corpus of ancient Indus Valley Script texts. The results of the analysis show a kind of patterning they argue is only found in glottographic, or speech-based, writing systems. The complex Indus Valley civilization flourished from 2,600 to 1,900 B.C. and left hundreds of engravings on seals and tablets -- writings which have yet to be deciphered.
In an article published in the April 24 issue of Sciences, researchers describe how they applied a computational process called "comparative entropy" to a corpus of ancient Indus Valley Script texts. The results of the analysis show a kind of patterning they argue is only found in glottographic, or speech-based, writing systems. The complex Indus Valley civilization flourished from 2,600 to 1,900 B.C. and left hundreds of engravings on seals and tablets -- writings which have yet to be deciphered.











 Paper, it turns out, is a very reliable backup medium for information. While it can burn or dissolve in water, good acid-free versions of paper are otherwise stable over the long term, cheap to warehouse, and oblivious to technological change because its pages are "eye-scanable." No special devices needed. Well-made, well-cared for paper can last 1,000 years easily, and probably reach 2,000 without much extra trouble.
Paper, it turns out, is a very reliable backup medium for information. While it can burn or dissolve in water, good acid-free versions of paper are otherwise stable over the long term, cheap to warehouse, and oblivious to technological change because its pages are "eye-scanable." No special devices needed. Well-made, well-cared for paper can last 1,000 years easily, and probably reach 2,000 without much extra trouble.
 Since its launch in 2005, Google Earth has become a valuable tool for sharing information of global scale. Its accessible platform and wide distribution has led to a wealth of independently created “layers” exploring a huge variety of topics.
Since its launch in 2005, Google Earth has become a valuable tool for sharing information of global scale. Its accessible platform and wide distribution has led to a wealth of independently created “layers” exploring a huge variety of topics.








{kind=link}