13 years, 2 months ago by Karin Wiecha
13 years, 2 months ago by Karin Wiecha
13 years, 2 months ago by Karin Wiecha
13 years, 3 months ago by Karin Wiecha
13 years, 3 months ago by Karin Wiecha
13 years, 4 months ago by Karin Wiecha
13 years, 6 months ago by Richard Makin
13 years, 7 months ago by Laura Welcher
13 years, 7 months ago by Richard Makin
13 years, 8 months ago by Laura Welcher
13 years, 10 months ago by Laura Welcher
13 years, 11 months ago by Austin Brown
14 years ago by Laura Welcher
14 years, 2 months ago by Laura Welcher
14 years, 3 months ago by
14 years, 9 months ago by Laura Welcher
14 years, 10 months ago by
15 years ago by Laura Welcher

Did you know...
There is something you can do to help document and promote the languages used in your own community! We need your help to meet our goal of recording 50 languages in a single day! How many languages can you help us document? Bring yourself and your multilingual friends and be the stars of your own grassroots language documentation project!
Professional linguists and videographers will be on site to document you and your friends speaking word lists, reading texts, and telling stories. You can also document your language using tools you probably have in your purse or back pocket — a mobile phone, digital camera, or laptop — just bring your device and our team will guide you through the documentation process.
How do your words and stories make a difference? An important part of language documentation is building a corpus — creating collections of vocabulary words, as well as conversations and stories that demonstrate language in use. From a corpus, linguists and speech technologists can build grammars, dictionaries, and tools that enable a language to be used online. The bigger the corpus, the better the tools!
The recordings you make during the event will be added to The Rosetta Project's open collection of all human language in The Internet Archive. And, you can compete for cool prizes, including an iPad 2 for the participant who records and uploads the most languages during the event!
Please
We will be in touch soon with more information about the day's events, and how you can participate! For questions or more information please contact rosetta@longnow.org.
15 years ago by Harry Willoughby
15 years ago by Colin Farlow
In a new study published in the journal Language and Cognition “When Time is Not Space,” a team of researchers from University of Portsmouth and Federal University of Rondonia claim that the Amondawa, a small Amazonian tribe, speak a language with a very uncommon conceptualization of time. The story was recently picked up by BBC, revealing that the debate about whether language influences thought is very much alive and newsworthy.

According to researchers Sinha et al., the Amondawa have no words for talking abstractly about time (as in the English word 'time'), or time periods (like 'year'):
“What we don't find is a notion of time as being independent of the events which are occurring; they don't have a notion of time which is something the events occur in.”
The mapping of time to physical space is commonly found in human language, and its absence in Amondawa is perhaps the most surprising result of the study. Rather than having a time-space metaphor, the Amondawa conceptualization of time is based on “social activity, kinship and ecological regularity.”
Pierre Pica, a theoretical linguist at France’s National Centre for Scientific Research, question the conclusions derived from this new research. Pica explains that just because Amondawa does not use cardinal chronology, does not mean they view themselves advancing through time any differently than the rest of us who use a cardinal chronological system.
Sinha et al. state that the tribe’s language in no way affects their cognitive ability to grasp temporal concepts -- they talk about events, and sequences of events, and learn Portuguese which does have abstract time expressions. Rather, the Amondawa language provides a different way of construing and talking about temporal concepts in daily life.
This contention about whether the Amondawa language affects its speakers’ thought processes hearkens back to a famous study by Benjamin Lee Whorf on the Hopi Language in the first half of the 20th century. This study was a foundational example for Whorf’s “linguistic relativity hypothesis” – the idea that the language you speak influences the way you think. From his study of Hopi, Whorf concluded:
“The Hopi language is seen to contain no words, grammatical forms, constructions or expressions that refer directly to what we call TIME, or to past, present or future, or to enduring or lasting…the Hopi language contains no reference to TIME, either explicit or implicit.” [1]
Whorf’s ideas about Hopi have received a great deal of criticism over the years, and his data was critiqued as erroneous evidence resulting from deficient research practices. [2] Nevertheless, the idea that language influences thought has certainly stuck around, and is now being raised by a new generation of researchers like Sinha et al who are gathering new data from small and threatened languages around the world.
For more on the relationship of language and thought, listen to our podcasts of previous Long Now seminars by Lera Boroditsky as well as Daniel Everett who talks about Pirahã, a language also from the Amazon.
[1] Whorf, Benjamin Lee. 1950. An American Indian Model of the Universe. The International Journal of American Linguistics 16(2).
[2] In an interview by BBC, Guy Deutscher explains his ideas about language and thought in addition to describing Benjamin Whorf’s research on Hopi Language.
The author of this post, Colin Farlow, is a 02011 summer intern with the Rosetta Project. He recently graduated from Indiana University, where he studied East Asian Languages and Cultures and Philosophy.
15 years, 3 months ago by Austin Brown
15 years, 8 months ago by Laura Welcher
15 years, 11 months ago by Adrienne Mamin
Egyptian Hieroglyphs on The Rosetta Stone were deciphered by scholars, but a new computer program written at MIT could potentially accomplish the same feat today:
“'Traditionally, decipherment has been viewed as a sort of scholarly detective game, and computers weren't thought to be of much use,’ study co-author and MIT computer science professor Regina Barzilay said in an email.” (quoted in this recent writeup in the National Geographic Daily News).
The language in this case is Ugaritic, written in cuneiform and last used in Syria more than three thousand years ago. Archaeologists discovered Ugaritic texts in 1928, but linguists didn’t finish deciphering them for another four years. The new computer program did it in a couple of hours.

While an exciting and significant first step, the program is not a silver bullet solution to language decipherment. Human beings figured out Ugaritic long before the computer program came along, and it remains to be seen how well the program works with a never-before-deciphered language. Furthermore, the program relied on comparisons between Ugaritic and a known and closely related language, Hebrew. There are some languages with no known close relatives, and in those cases, the computer program would be at a loss.
Of course, we can’t be certain exactly how the technology may progress in the future. But with the Rosetta Disk designed to last for thousands of years, and with hundreds of languages classified in the Ethnologue as nearly extinct, an automated decoder of language documentation seems likely to prove useful eventually. It’s nice to know we’ve made a promising start.
15 years, 11 months ago by Laine Stranahan
The Rosetta Project is pleased to announce the Parallel Speech Corpus Project, a year-long volunteer-based effort to collect parallel recordings in languages representing at least 95% of the world's speakers. The resulting corpus will include audio recordings in hundreds of languages of the same set of texts, each accompanied by a transcription. This will provide a platform for creating new educational and preservation-oriented tools as well as technologies that may one day allow artificial systems to comprehend, translate, and generate them.
Huge text and speech corpora of varying degrees of structure already exist for many of the most widely spoken languages in the world---English is probably the most extensively documented, followed by other majority languages like Russian, Spanish, and Portuguese. Given some degree of access to these corpora (though many are not publicly accessible), research, education and preservation efforts in the ten languages which represent 50% of the world's speakers (Mandarin, Spanish, English, Hindi, Urdu, Arabic, Bengali, Portuguese, Russian and Japanese) can be relatively well-resourced.
But what about the other half of the world? The next 290 most widely spoken languages account for another 45% of the population, and the remaining 6,500 or so are spoken by only 5%--this latter group representing the "long tail" of human languages:
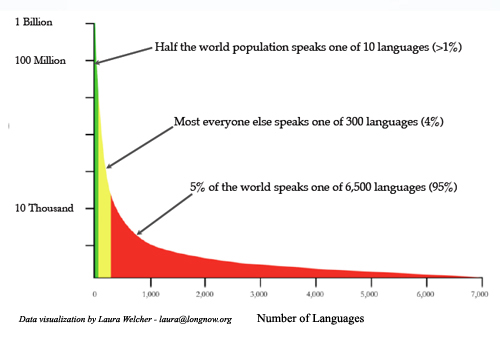
Equal documentation of all the world's languages is an enormous challenge, especially in light of the tremendous quantity and diversity represented by the long tail. The Parallel Speech Corpus Project will take a first step toward universal documentation of all human languages, with the goal of providing documentation of the top 300 and providing a model that can then be extended out to the long tail. Eventually, researchers, educators and engineers alike should have access to every living human language, creating new opportunities for expanding knowledge and technology alike and helping to preserve our threatened diversity.
This project is made possible through the support and sponsorship of speech technology expert James Baker and will be developed in partnership with his ALLOW initiative. We will be putting out a call for volunteers soon. In the meantime, please contact rosetta@longnow.org with questions or suggestions.
15 years, 11 months ago by Adrienne Mamin

Description of Yurok numerals
in the Rosetta archiveYurok (YUR) is the language of the Yurok people of northwestern California. As with most indigenous American languages, European contact has mostly come to replace Yurok with English, so that as of 2009 it is near extinction. Yurok belongs to the Algonquian language family, most of whose other members are geographically distant from Yurok. Accordingly, Yurok is surrounded by languages unrelated to it, except for the only distantly related (and extinct) Wiyot.
Yurok has a set of glottalized consonants (sounds produced with the glottis closed, as if holding your breath) that contrast with their nonglottalized counterparts. The glottalized sounds are less common but are important in Yurok morphology, such as verb conjugations.
Some verbs must inflect (be conjugated) for person and number, others cannot, and many can go either way. For example, the word for eating must take different endings according to the subject: nepek’ for ‘I eat,’ nepe’m for ‘you (singular) eat,’ nep’ for ‘s/he eats,’ nepoh for ‘we eat,’ nepu’ for ‘you (plural) eat,’ and nepehl for ‘they eat.' On the other hand, chek ‘sit,’ always maintains the same form no matter who and how many are sitting. Finally, skewok ‘want’ can remain skewok for all subjects, or it can inflect as skewoksimek’ ‘I want,’ skewoksime’m ‘you (singular) want,’ skewoksi’m ‘s/he wants,’ etc., just as the verb ‘eat’ does.
Yurok has no distinct category of adjectives; the words that translate to adjectives or express adjective-like meanings behave like verbs in terms of word order and inflection. For example, there is a word for being big that inflects just as verbs do: peloyek’ ‘I am big,’ peloye’m ‘you are big,’ pelo’y ‘s/he is big,’ etc. Numerals are also a type of verb, and they have different forms according to the type or shape of thing being enumerated (for example, humans versus animals, or flat things versus tufted things).
Ways of writing Yurok have varied over time and remain not entirely settled. In the 1980s the Yurok Language Committee adopted UNIFON, designed (by an economist) as an English pronunciation key. However, UNIFON was impractical and therefore unpopular, and the Yurok Language Committee adopted an alternative system, which was later revised by linguists working on the language (as Leanne Hinton details in her unpublished 2010 article "Orthography Wars"). The Berkeley Yurok Language Project, a searchable collection of Yurok stories, words, and morphemes, lists entries in both the original alternative system and the revised system.

16 years, 1 month ago by Sarina Spector

"Language is identity," Darfur refugee Daowd I. Salih told the New York Times about a week ago. He was being interviewed for an article called "Listening to (and Saving) the World's Languages." As mentioned in this Rosetta Project blog post, the article discusses the amazing variety of spoken languages in New York City, and what residents are doing (or not doing) to preserve their native language.
One of the languages the article touches on is Ormuri, a language of multiple dialects spoken in small regions of Afghanistan and Pakistan. According to the Ethnologue, Ormuri has only about 1,050 speakers. The New York Times article reveals a plan to canvass New York City for speakers of Ormuri in order to learn more about the language and the cultural information it holds.
Languages with small speaker populations are quickly dying out, and the data they contain (whether it be linguistic, historical, or cultural) is important enough to merit a concerted effort at saving them. Ormuri is a perfect example, especially in the political and economic environment of our time (read: the complex tangle that is our current Middle Eastern relations). The Rosetta Project's database in the Internet Archive contains a detailed description of Ormuri, including a history of its speakers: where they came from, who their ancestors are, and how their language has co-evolved with those around it to become what it is today.
In my mind there is nothing that illustrates a culture's unity so much as its language. It allows people to build social relationships, conduct business transactions, and express to fellow humans everything they hold dear. What's more, as any good anthropologist knows, learning the language of a culture is one of the most important steps an outsider can take to gain the trust and respect of its people.
What does this have to do with an obscure Afghan language, or with Darfur refugees? Only this: if we intend to successfully navigate the conflicts of the modern global world, it is absolutely necessary to understand and relate to the people with whom we intend to work. The Middle East in particular, Afghanistan being an illustrative example, is culturally very foreign to the West; its people have lived for centuries in small, autonomous groups that hold to varied, often contradictory beliefs. The fact that so many of these groups have their own language, like Ormuri, is telling of their relative isolation, and gives clues to how they live their lives.
Rosetta's description of Ormuri tells the story of its peoples' interactions through Ormuri's morphology. By studying the languages Ormuri had contact with and how these influenced its words, we can begin to create a web of social and economic interaction that would show the connections and dissociations between groups in the area. For example, Ormuri has many morphological similarities to Pashto, a common language in the region of Waziristan where Ormuri is spoken. Ormuri pronouns are strikingly similar to their Pashto equivalents, and many scattered words share similarities, like "wife," "glitter," and "to sit down." Pashto has also phonetically influenced Ormuri, replacing some traditional Ormuri allophones with similar Pashto ones.
Ormuri has also sustained contact with Persian, which is evident in many morphological changes that mimic the latter: loss of gendered nouns, simplification of plural nouns, and reduction of irregular past participles. Analyzing this data led the author, Georg Morgenstierne, to doubt the previous belief that Ormuri speakers descend from Kurds, and provided evidence for further theoretical investigations.
The very existence of this kind of knowledge is what Rosetta is all about; by preserving minority languages and stressing their importance, we hope to contribute vital insights into the lives of their speakers, insights that can be put to good use in surprising places. After all, you never know who you'll meet on the New York City subway.
[A note of introduction: this is my first post as an intern with the Rosetta Project. I will be working with Rosetta for three months, building the collection in the Internet Archive and continuing to spotlight Rosetta material on this blog.]
16 years, 1 month ago by Laura Welcher

The New York Times ran an article today about endangered languages spoken within the New York City immigrant population - by some estimates as many as 800 languages are represented:
"In addition to dozens of Native American languages, vulnerable foreign languages that researchers say are spoken in New York include Aramaic, Chaldic and Mandaic from the Semitic family; Bukhari (a Bukharian Jewish language, which has more speakers in Queens than in Uzbekistan or Tajikistan); Chamorro (from the Mariana Islands); Irish Gaelic; Kashubian (from Poland); indigenous Mexican languages; Pennsylvania Dutch; Rhaeto-Romanic (spoken in Switzerland); Romany (from the Balkans); and Yiddish."
The article designates New York City as "the most linguistically diverse city in the world." I don't know if that is in fact true, but it seems likely.
For the United States, there is data compiled by the US Census on language use - since 1980, the long form of the census has asked several questions about language use - Does this person speak a language other than English at home? If so, what is this language (fill in the blank)? How well does this person speak English (very well, well, not well, not at all)? Since the long form is distributed to one in ten households, the smaller the group the less accurate the count tends to be. Still, the numbers give some idea, and it is always interesting to see what languages get listed.
For 2008, the US Census compiled data on the languages spoken at home for cities with 100,000 or more people. The column that is especially interesting for endangered languages is the "other languages" category - that is not English or Spanish, not other Indo-European, and not Asian or Pacific. New York City tops this list with 179,000 speakers of other languages (60,000 of whom are dominant in this language). Los Angeles is next with 43,000 speakers of other languages. San Francisco is #32 on the list with 5,700 speakers of other languages.
To make better use of the wealth of linguistic diversity in their own backyard, Daniel Kaufman and colleagues at The City University of New York have started the independent Endangered Language Alliance - "an urban initiative for endangered language research and conservation." This is, in fact, a time honored tradition among linguistic graduate students and faculty who lack time or resources to travel. But judging by the numbers of speakers of small languages in large cities, and the rapid loss of small languages around the world, this kind of program is just plain smart. Having more of them in urban locales - or maybe existing programs like StoryCorps - could use "diaspora sourcing" to make a big impact in the documentation and revitalization of endangered languages.